Umgang mit Leerzeichen
Das Vorhandensein von Leerzeichen im DOM kann zu Layoutproblemen führen und die Manipulation des Inhaltsbaums auf unerwartete Weise erschweren, je nachdem, wo sie sich befinden. In diesem Artikel wird untersucht, wann Schwierigkeiten auftreten können und was getan werden kann, um die daraus resultierenden Probleme zu mildern.
Was sind Leerzeichen?
Leerzeichen-Zeichen bestehen in verschiedenen Programmierkontexten aus unterschiedlichen Zeichen. Dokument-Leerzeichen-Zeichen umfassen laut den CSS-Verarbeitungsregeln für Leerzeichen nur Leerzeichen (U+0020), Tabs (U+0009), Zeilenumbrüche (LF, U+000A) und Wagenrückläufe (CR, U+000D), wobei CR-Zeichen in jeder Hinsicht als Leerzeichen gelten. Diese Zeichen ermöglichen es Ihnen, Ihren Code zu formatieren, um die Lesbarkeit zu verbessern. Ein Großteil unseres Quellcodes ist voll von diesen Leerzeichen, und wir neigen dazu, sie nur als Teil eines Produktions-Build-Schritts zu entfernen, um die Dateigröße zu reduzieren.
Beachten Sie, dass diese Liste keine geschützten Leerzeichen (U+00A0, in HTML) enthält. Diese Zeichen lösen daher kein Zusammenfallen aus, weshalb sie häufig verwendet werden, um längere Abstände in HTML zu erzeugen.
CSS definiert auch das Konzept der Segmentbrüche, die im Kontext von HTML äquivalent zu LF-Zeichen sind.
Wie verarbeitet HTML Leerzeichen?
Es ist ein häufiger Mythos, dass "HTML Leerzeichen ignoriert", was nicht wahr ist: HTML bewahrt alle Leerzeichen im Textinhalt genauso, wie Sie sie im Quellcode geschrieben haben. Als Markup-Sprache erzeugt HTML ein DOM, in dem alle Leerzeichen im Textinhalt erhalten bleiben. Diese können über DOM-APIs wie Node.textContent abgerufen und manipuliert werden. Wenn HTML Leerzeichen aus dem DOM entfernen würde, könnte CSS, eine nachgelagerte Rendering-Engine, die auf dem DOM arbeitet, diese nicht mit der white-space-Eigenschaft bewahren.
Hinweis: Um klar zu sein, wir sprechen hier von Leerzeichen zwischen HTML-Tags, die im DOM zu Textknoten werden. Jedes Leerzeichen innerhalb eines Tags (zwischen den Winkelklammern, aber nicht als Attributwert) ist nur Teil der HTML-Syntax und erscheint nicht im DOM.
Hinweis:
Aufgrund des "Magischen" der HTML-Parsing (Zitat aus DOM-Spezifikation) gibt es bestimmte Stellen, an denen Leerzeichen ignoriert werden könnten. Zum Beispiel werden Leerzeichen zwischen den öffnenden Tags <html> und <head> oder zwischen den schließenden Tags </body> und </html> ignoriert und erscheinen nicht im DOM. Außerdem wird beim Parsen des Textinhalts des <pre>-Elements ein einzelnes führendes Zeilenumbruchzeichen entfernt. Wir ignorieren diese Randfälle.
Des Weiteren normalisiert der HTML-Parser bestimmte Leerzeichen: Es ersetzt CR- und CRLF-Sequenzen durch einen einzelnen Zeilenumbruch. CR-Zeichen können jedoch entweder über Zeichenreferenzen oder JavaScript in das DOM eingefügt werden, sodass die CSS-Leerzeichenverarbeitungsregeln trotzdem definieren müssen, wie sie zu handhaben sind.
Betrachten Sie zum Beispiel das folgende Dokument:
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
Der DOM-Baum dazu sieht folgendermaßen aus:

Beachten Sie, dass:
- Einige Textknoten nur Leerzeichen enthalten werden.
- Andere Textknoten möglicherweise Leerzeichen am Anfang oder Ende haben.
Hinweis: Firefox DevTools unterstützt das Hervorheben von Textknoten und erleichtert es, genau zu sehen, welche Knoten Leerzeichen enthalten. Reine Leerzeichenelemente werden mit einem "Leerzeichen"-Label markiert.
Die Bewahrung von Leerzeichen im DOM ist in vielerlei Hinsicht nützlich, kann jedoch bestimmte Layouts schwieriger machen und Probleme für Entwickler verursachen, die über DOM-Knoten iterieren möchten. Diese Probleme und einige Lösungen werden wir später im Abschnitt Lösen häufiger Probleme mit Leerzeichenknoten betrachten.
Wie verarbeitet CSS Leerzeichen?
Wenn das DOM zur Darstellung an CSS übergeben wird, werden die Leerzeichen standardmäßig weitgehend entfernt. Das bedeutet, dass die Formatierung Ihres Codes für den Endbenutzer nicht sichtbar ist — das Erstellen von Platz um und innerhalb der Elemente ist die Aufgabe von CSS.
<!doctype html>
<h1> Hello World! </h1>
Dieser Quellcode enthält ein paar Zeilenumbrüche nach dem doctype und eine Reihe von Leerzeichen vor, nach und innerhalb des <h1>-Elements. Aber der Browser ignoriert diese Leerzeichen und zeigt einfach die Worte "Hello World!" an, als ob diese Zeichen überhaupt nicht existierten:
CSS ignoriert die meisten, aber nicht alle Leerzeichen. In diesem Beispiel existiert eines der Leerzeichen zwischen "Hello" und "World!" weiterhin, wenn die Seite in einem Browser angezeigt wird. CSS verwendet einen spezifischen Algorithmus, um zu entscheiden, welche Leerzeichen für den Benutzer irrelevant sind und wie sie entfernt oder transformiert werden. Wir erklären, wie diese Verarbeitung in den nächsten Abschnitten funktioniert.
Collapsing und Transformation
Betrachten wir ein Beispiel. Um die Leerzeichen deutlicher zu machen, haben wir auch einen Kommentar hinzugefügt, in dem alle Leerzeichen als ◦, alle Tabs als ⇥ und alle Zeilenumbrüche als ⏎ dargestellt werden:
<h1> Hello
<span> World!</span> </h1>
<!--
<h1>◦◦◦Hello◦⏎
⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>
-->
Dieses Beispiel wird im Browser wie folgt gerendert:
Das <h1>-Element enthält:
- Einen Textknoten (bestehend aus einigen Leerzeichen, dem Wort "Hello", einem Zeilenumbruch und einigen Tabs).
- Ein Inline-Element (
<span>, das ein Leerzeichen und das Wort "World!" enthält). - Einen weiteren Textknoten (mit einem Tabulator und Leerzeichen nach dem
<span>).
Da dieses <h1>-Element nur Inline-Elemente enthält, erstellt es einen Inline-Formatierungskontext. Dies ist einer der mehreren Layout-Rendering-Kontexte, die von Browser-Engines verwendet werden, um Inhalte auf der Seite anzuordnen.
Innerhalb dieses Inline-Formatierungskontexts werden Leerzeichen wie folgt verarbeitet:
Hinweis:
Dieser Algorithmus kann über die Eigenschaft white-space-collapse (oder deren Kurzform white-space) konfiguriert werden. Wir beginnen mit der Annahme ihres Standardwerts (white-space-collapse: collapse) und betrachten dann, wie verschiedene Eigenschaftswerte diesen Algorithmus beeinflussen.
-
Zuerst werden alle Leerzeichen und Tabs unmittelbar vor und nach einem Zeilenumbruch ignoriert. Also, wenn wir unser vorheriges Markup-Beispiel nehmen:
html<h1>◦◦◦Hello◦⏎ ⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>...und diese erste Regel anwenden, erhalten wir:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>⇥◦◦</h1> -
Als nächstes werden aufeinanderfolgende Zeilenumbrüche auf einen einzigen Zeilenumbruch reduziert. In diesem Beispiel haben wir keine.
-
Danach werden Zeilen im Quellcode in einzelne Zeilen zusammengefügt, indem alle verbleibenden Zeilenumbruchzeichen entfernt werden. Sie werden entweder in Leerzeichen (U+0020) umgewandelt oder einfach entfernt, abhängig vom Kontext vor und nach dem Umbruch. Die genaue Wahl zwischen den beiden ist browser- und sprachabhängig. In unserem hier gezeigten Beispiel in Englisch (wo Leerzeichen Wörter trennen), können wir erwarten, dass alle Zeilenumbrüche in Leerzeichen "transformiert" werden. So enden wir mit:
html<h1>◦◦◦Hello◦<span>◦World!</span>◦◦◦</h1>Besonders in Sprachen, die keine Worttrenner haben, wie Chinesisch, werden Zeilen ohne dazwischenliegende Leerzeichen verbunden. Somit:
html<div>你好 世界</div>könnte als "你好世界" ohne irgendwelche Leerzeichen dazwischen gerendert werden, je nach Heuristik des Browsers.
-
Danach werden alle Tabulatorzeichen in Leerzeichen umgewandelt, so dass das Beispiel wird:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>◦◦◦</h1> -
Anschließend wird jedes Leerzeichen, das unmittelbar auf ein anderes Leerzeichen folgt (auch zwischen zwei separaten Inline-Elementen), ignoriert, sodass wir enden mit:
html<h1>◦Hello◦<span>World!</span>◦</h1>
Deshalb sehen die Leute, die die Webseite besuchen, den Satz "Hello World!" schön geschrieben am Anfang der Seite, statt eines seltsam eingerückten "Hello" gefolgt von einem noch seltsamer eingerückten "World!" in der nächsten Zeile.
Nach diesen Schritten verarbeitet der Browser den Zeilenumbruch und den bidirektionalen Text, die wir hier ignorieren werden. Beachten Sie, dass es immer noch Leerzeichen nach dem öffnenden <h1>-Tag und vor dem schließenden </h1>-Tag gibt, aber diese werden im Browser nicht gerendert. Wir werden das als Nächstes behandeln, wenn jede Zeile ausgelegt ist.
Verschiedene white-space-collapse-Werte überspringen verschiedene Schritte dieses Algorithmus:
preserveundbreak-spaces: Der gesamte Algorithmus wird übersprungen, und es erfolgt keine Kollabierung oder Transformation der Leerzeichen.preserve-breaks: Die Schritte 2 und 3 werden übersprungen, und Zeilenumbrüche werden beibehalten.preserve-spaces: Der gesamte Algorithmus wird übersprungen und durch einen einzigen Schritt ersetzt, um jeden Tabulator oder Zeilenumbruch in einen Leerraum zu verwandeln.
In Kürze werden verschiedene Leerzeichen-Zeichen wie folgt kollabiert und transformiert:
- Tabs werden im Allgemeinen in Leerzeichen umgewandelt.
- Wenn Segmentbrüche kollabiert werden sollen:
- Sequenzen von Segmentbrüchen werden auf einen einzigen Segmentbruch reduziert.
- Sie werden in Sprachen, die Wörter mit Leerzeichen trennen (wie Englisch), in Leerzeichen umgewandelt oder in Sprachen, die Wörter nicht mit Leerzeichen trennen (wie Chinesisch), vollständig entfernt.
- Wenn Leerzeichen kollabiert werden sollen:
- Leerzeichen oder Tabs vor oder nach Segmentbrüchen werden entfernt.
- Sequenzen von Leerzeichen werden auf ein einziges Leerzeichen reduziert.
- Wenn Leerzeichen erhalten bleiben, werden Sequenzen von Leerzeichen als nicht brechend behandelt, es sei denn, sie blättern am Ende jeder Sequenz – das heißt, die nächste Zeile beginnt immer mit dem nächsten Zeichen, das kein Leerzeichen ist. Im Fall des
break-spaces-Werts könnte jedoch an jedem Leerzeichen ein weicher Zeilenumbruch auftreten, sodass die nächste Zeile mit einem oder mehreren Leerzeichen beginnen kann.
Kürzen und Positionieren
In sowohl Inline als auch Block Formatierungskontexten werden Elemente in Zeilen angeordnet. In einem Inline-Formatierungskontext werden Zeilen durch Textumbruch erstellt. In einem Block-Formatierungskontext hingegen bildet jeder Block seine eigene Zeile. Während jede Zeile ausgelegt wird, werden Leerzeichen weiter verarbeitet. Schauen wir uns ein Beispiel an, um zu erklären, wie das funktioniert.
In diesem Beispiel, wie zuvor, haben wir die Leerzeichen-Zeichen in einem Kommentar markiert. Wir haben drei Textknoten, die nur Leerzeichen enthalten: einen vor dem ersten <div>, einen zwischen den 2 <div>s und einen nach dem zweiten <div>.
<body>
<div> Hello </div>
<div> World! </div>
</body>
<!--
<body>⏎
⇥<div>⇥Hello⇥</div>⏎
⏎
◦◦◦<div>◦◦World!◦◦</div>◦◦⏎
</body>
-->
Dies wird wie folgt gerendert:
Die Leerzeichen in diesem Beispiel werden wie folgt behandelt:
Hinweis:
Dieser Algorithmus kann über die Eigenschaft white-space-collapse (oder deren Kurzform white-space) konfiguriert werden. Wir beginnen mit der Annahme ihres Standardwerts (white-space-collapse: collapse) und betrachten dann, wie verschiedene Eigenschaftswerte diesen Algorithmus beeinflussen.
-
Zuerst wird das Leerzeichen kollabiert in derselben Weise, wie wir es im vorherigen Abschnitt gesehen haben, indem dies:
html<body>⏎ ⇥<div>⇥Hello⇥</div>⏎ ⏎ ◦◦◦<div>◦◦World!◦◦</div>◦◦⏎ </body>...in dies verwandelt wird:
html<body>◦<div>◦Hello◦</div>◦<div>◦World!◦</div>◦</body>Zeilen werden dann entsprechend dem Block-Formatierungskontext ausgelegt, der vom
<body>-Element erstellt wird. In diesem Beispiel wird jeder der fünf Kindknoten von<body>als separate Zeile ausgelegt. (Jede Zeile in diesem Codeblock stellt eine Zeile im gerenderten Layout dar, nicht eine Zeile in unserem ursprünglichen HTML-Code):html<body> ◦ <div>◦Hello◦</div> ◦ <div>◦World!◦</div> ◦ </body>Beachten Sie, dass, wenn die Zeilen zu lang werden, jede Zeile umgebrochen wird und mehr Zeilen entstehen. Tatsächlich bestimmen Browser den Inhalt der Zeilen, während die Zeilen ausgelegt werden. Wir überspringen den Teil, wie Textumbruch funktioniert.
-
Sequenzen von Leerzeichen am Anfang einer Zeile werden entfernt, sodass das Beispiel wird:
html<body> <div>Hello◦</div> <div>World!◦</div> </body> -
Jeder jetzt erhaltene Tabulator wird gemäß
tab-sizegerendert. Dies kann nur geschehen, wennwhite-space-collapseaufpreserveoderbreak-spacesgesetzt ist, da alle anderen Einstellungen Tabs in Leerzeichen umwandeln. -
Sequenzen von Leerzeichen am Ende einer Zeile werden entfernt, sodass das oben Genannte wird:
html<body> <div>Hello</div> <div>World!</div> </body>
Die drei leeren Zeilen, die wir jetzt haben, werden im endgültigen Layout keinen Platz einnehmen, da sie keinen sichtbaren Inhalt enthalten. So werden wir letztendlich nur zwei Zeilen sehen, die Platz auf der Seite einnehmen. Die Besucher der Webseite sehen die Wörter "Hello" und "World!" in zwei separaten Zeilen, genau so, wie Sie es erwarten würden, wenn zwei <div>-Elemente ausgelegt werden. Browser ignorieren im Wesentlichen alle Leerzeichen, die im HTML-Code enthalten waren.
Verschiedene white-space-collapse-Werte überspringen verschiedene Schritte dieses Algorithmus:
preserveundbreak-spaces: Der gesamte Algorithmus wird bis auf Schritt 3 übersprungen, sodass keine Kollabierung oder Transformation der Leerzeichen erfolgt.preserve-spaces: Der gesamte Algorithmus wird übersprungen, sodass Leerzeichen am Anfang und Ende von Zeilen erhalten bleiben.preserve-breaks: Der gleiche Algorithmus wird angewendet wie beimcollapse-Wert.
Wie verarbeiten DOM-APIs Leerzeichen?
Wie zuvor erwähnt, werden Leerzeichen im DOM bewahrt. Das bedeutet, dass, wenn Sie Node.textContent abrufen, Sie den Textinhalt genauso erhalten, wie Sie ihn im HTML-Quellcode geschrieben haben. Wenn Sie Node.childNodes abrufen, erhalten Sie alle Textknoten, einschließlich derjenigen, die nur Leerzeichen enthalten.
Nicht alle DOM-APIs bewahren Leerzeichen; einige APIs beziehen sich auf den gerenderten Text. Beispielsweise gibt HTMLElement.innerText den Text genau so zurück, wie er gerendert wurde, mit allen collabierten und gekürzten Leerzeichen. Selection.toString() gibt den Text so zurück, wie er eingefügt würde, was im Allgemeinen bedeutet, dass Leerzeichen collabiert sind. In Firefox (der Leerzeichen zwischen chinesischen Zeichen, wie im Abschnitt collapsing and transformation erwähnt, collabiert), werden die collabierten Leerzeichen sowohl in dem von toString() zurückgegebenen String als auch im eingefügten Text weiterhin bewahrt.
<div id="test">Hello world!</div>
const div = document.getElementById("test");
console.log(div.textContent); // " Hello\n world!\n"
console.log(div.innerText); // "Hello world!"
const selection = document.getSelection();
selection.selectAllChildren(div);
console.log(selection.toString()); // "Hello world!"
Lösen häufiger Probleme mit Leerzeichenknoten
Leerzeichenknoten sind aufgrund der CSS-Verarbeitungsregeln für den Besucher der Website unsichtbar, können jedoch bestimmte Layouts und DOM-Manipulationen stören, die auf der genauen Struktur des DOM basieren. Schauen wir uns einige häufige Probleme an und wie man sie löst.
Leerzeichenverarbeitung zwischen Inline- und Inline-Block-Elementen
Schauen wir uns ein Layoutproblem mit Leerzeichenknoten an: Leerzeichen zwischen Inline- und Inline-Block-Elementen. Wie wir bereits bei Inline- und Blockelementen gesehen haben, werden die meisten Leerzeichen ignoriert, aber worttrennende Zeichen wie Leerzeichen bleiben erhalten. Die zusätzlichen Leerzeichen, die im Layout enthalten sind, dienen dazu, die Wörter im Satz zu trennen.
Bei inline-block-Elementen wird es interessanter: Diese Elemente verhalten sich wie Inline-Elemente außen und wie Blöcke innen. (Sie werden oft verwendet, um komplexere UI-Elemente, die nebeneinander auf derselben Linie platziert sind, wie Navigationsmenüpunkte, anzuzeigen.) Jedes Leerzeichen zwischen benachbarten Inline- oder Inline-Block-Elementen führt im Layout zu Leerzeichen, genau wie die Leerzeichen zwischen Wörtern im Text. (Dies kann Entwickler überraschen, da es sich um Blöcke handelt und Blöcke normalerweise keine zusätzlichen Leerzeichen anzeigen.)
Betrachten Sie dieses Beispiel (wie zuvor haben wir einen Kommentar im HTML-Code eingefügt, um die Leerzeichenzeichen zu zeigen):
.people-list {
list-style-type: none;
margin: 0;
padding: 0;
}
.people-list li {
display: inline-block;
width: 2em;
height: 2em;
background: #ff0066;
border: 1px solid;
}
<ul class="people-list">
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul>
<!--
<ul class="people-list">⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
</ul>
-->
Dies wird wie folgt gerendert:
Sie möchten wahrscheinlich nicht die Abstände zwischen den Blöcken. Abhängig von Ihrem Anwendungsfall (wie einer Liste von Avataren oder einer horizontalen Reihe von Navigationsschaltflächen) möchten Sie wahrscheinlich, dass die Elemente direkt nebeneinander liegen und dass Sie einen Abstand selbst steuern können.
Der Firefox DevTools HTML Inspector kann Textknoten hervorheben und zeigt Ihnen auch genau den Bereich an, den die Elemente einnehmen. Das ist nützlich, um herauszufinden, ob Sie vermuten, dass es zusätzliche Abstände oder unerwartete Leerzeichen gibt, die Lücken verursachen.
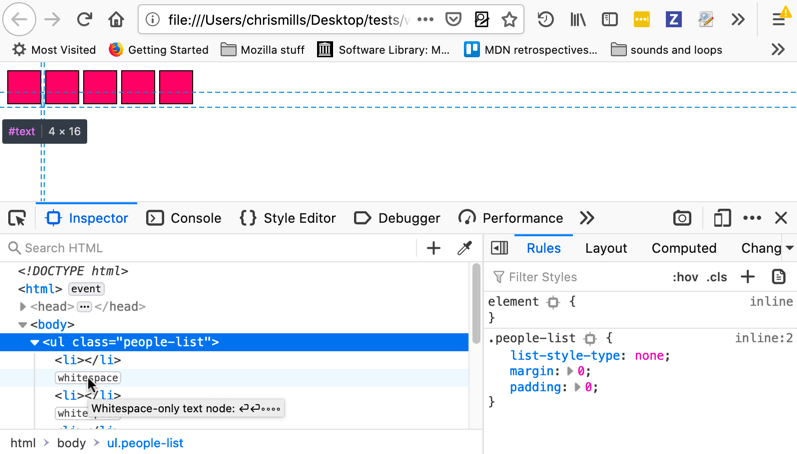
Es gibt einige Möglichkeiten, dieses Problem zu umgehen:
-
Verwenden Sie Flexbox, um die horizontale Liste von Elementen zu erstellen, anstatt eine
inline-block-Lösung zu versuchen. Flexbox regelt den Abstand und die Ausrichtung für Sie und ist definitiv die bevorzugte Lösung:cssul { list-style-type: none; margin: 0; padding: 0; display: flex; } -
Wenn Sie auf
inline-blockangewiesen sind, könnten Sie diefont-sizeder Liste auf0setzen. Dies funktioniert nur, wenn die Blöcke nicht mitem-Einheiten dimensioniert werden (daemauffont-sizebasiert, würde auch die Blockgröße mit0dimensioniert sein). Die Verwendung vonrem-Einheiten wäre hier eine gute Wahl:cssul { font-size: 0; /* … */ } li { display: inline-block; width: 2rem; height: 2rem; /* … */ } -
Alternativ könnten Sie einen negativen Rand auf die Listenelemente setzen:
cssli { display: inline-block; width: 2rem; height: 2rem; margin-right: -0.25rem; } -
Sie können dieses Problem auch lösen, indem Sie Leerzeichenknoten zwischen den
<li>-Elementen vermeiden:html<li> ... </li><li> ... </li>
Arbeiten mit Leerzeichen im DOM
Wie bereits erwähnt, werden Leerzeichen beim Rendern collabiert und gekürzt, aber im DOM bewahrt. Dies kann einige Fallstricke verursachen, wenn versucht wird, DOM-Manipulationen in JavaScript vorzunehmen. Zum Beispiel, wenn Sie eine Referenz zu einem übergeordneten Knoten haben und dessen erstes Elementkind mit Node.firstChild manipulieren möchten, würde ein unerwünschter Leerzeichenknoten direkt nach dem öffnenden übergeordneten Tag Ihnen das falsche Ergebnis liefern. Der Textknoten würde anstelle des Elements ausgewählt, das Sie anvisieren möchten.
Ein weiteres Beispiel: Wenn Sie etwas mit einer Teilmenge von Elementen tun möchten, basierend darauf, ob sie leer sind (keine Kindknoten haben), könnten Sie Node.hasChildNodes() verwenden. Aber wenn eines dieser Elemente Textknoten enthält, könnten Sie falsche Ergebnisse erhalten.
Der folgende JavaScript-Code zeigt mehrere Funktionen, die den Umgang mit Leerzeichen im DOM erleichtern:
/**
* Throughout, whitespace is defined as one of the characters
* "\t" TAB \u0009
* "\n" LF \u000A
* "\r" CR \u000D
* " " SPC \u0020
*
* This does not use JavaScript's "\s" because that includes non-breaking
* spaces (and also some other characters).
*/
/**
* Determine whether a node's text content is entirely whitespace.
*
* @param nod A node implementing the `CharacterData` interface (i.e.,
* a `Text`, `Comment`, or `CDATASection` node)
* @return `true` if all of the text content of `nod` is whitespace,
* otherwise `false`.
*/
function isAllWs(nod) {
return !/[^\t\n\r ]/.test(nod.textContent);
}
/**
* Determine if a node should be ignored by the iterator functions.
*
* @param nod An object implementing the `Node` interface.
* @return `true` if the node is:
* 1) A `Text` node that is all whitespace
* 2) A `Comment` node
* and otherwise `false`.
*/
function isIgnorable(nod) {
return (
nod.nodeType === 8 || // a comment node
(nod.nodeType === 3 && isAllWs(nod))
); // a text node, all ws
}
/**
* Version of `previousSibling` that skips nodes that are entirely
* whitespace or comments. (Normally `previousSibling` is a property
* of all DOM nodes that gives the sibling node, the node that is
* a child of the same parent, that occurs immediately before the
* reference node.)
*
* @param sib The reference node.
* @return The closest previous sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null` if
* no such node exists.
*/
function nodeBefore(sib) {
while ((sib = sib.previousSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `nextSibling` that skips nodes that are entirely
* whitespace or comments.
*
* @param sib The reference node.
* @return The closest next sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null`
* if no such node exists.
*/
function nodeAfter(sib) {
while ((sib = sib.nextSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `lastChild` that skips nodes that are entirely
* whitespace or comments. (Normally `lastChild` is a property
* of all DOM nodes that gives the last of the nodes contained
* directly in the reference node.)
*
* @param sib The reference node.
* @return The last child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function lastChild(par) {
let res = par.lastChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.previousSibling;
}
return null;
}
/**
* Version of `firstChild` that skips nodes that are entirely
* whitespace and comments.
*
* @param sib The reference node.
* @return The first child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function firstChild(par) {
let res = par.firstChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.nextSibling;
}
return null;
}
/**
* Version of `data` that doesn't include whitespace at the beginning
* and end and normalizes all whitespace to a single space. (Normally
* `data` is a property of text nodes that gives the text of the node.)
*
* @param txt The text node whose data should be returned
* @return A string giving the contents of the text node with
* whitespace collapsed.
*/
function dataOf(txt) {
let data = txt.textContent;
data = data.replace(/[\t\n\r ]+/g, " ");
if (data[0] === " ") {
data = data.substring(1, data.length);
}
if (data[data.length - 1] === " ") {
data = data.substring(0, data.length - 1);
}
return data;
}
Der folgende Code demonstriert die Verwendung der obigen Funktionen. Er iteriert über die Kinder eines Elements (dessen Kinder alle Elemente sind), um dasjenige zu finden, dessen Text "This is the third paragraph" ist, und ändert dann den Klassenattribut und den Inhalt dieses Absatzes.
let cur = firstChild(document.getElementById("test"));
while (cur) {
if (dataOf(cur.firstChild) === "This is the third paragraph.") {
cur.className = "magic";
cur.firstChild.textContent = "This is the magic paragraph.";
}
cur = nodeAfter(cur);
}