Übersicht Client-Server
Jetzt, da Sie den Zweck und die potenziellen Vorteile der serverseitigen Programmierung kennen, werden wir im Detail untersuchen, was passiert, wenn ein Server eine "dynamische Anfrage" von einem Browser erhält. Da der Großteil des serverseitigen Codes einer Website Anfragen und Antworten auf ähnliche Weise bearbeitet, wird Ihnen dies helfen zu verstehen, was Sie tun müssen, wenn Sie Ihren eigenen Code schreiben.
| Voraussetzungen: | Ein grundlegendes Verständnis davon, was ein Webserver ist. |
|---|---|
| Ziel: | Verstehen der Client-Server-Interaktionen in einer dynamischen Website und insbesondere welche Operationen durch serverseitigen Code ausgeführt werden müssen. |
Es gibt keinen realen Code in der Diskussion, da wir noch kein Web-Framework ausgewählt haben, um unseren Code zu schreiben! Diese Diskussion ist jedoch immer noch sehr relevant, weil das beschriebene Verhalten von Ihrem serverseitigen Code implementiert werden muss, unabhängig von welcher Programmiersprache oder welchem Web-Framework Sie wählen.
Webserver und HTTP (eine Einführung)
Webbrowser kommunizieren mit Webservern mittels des HyperText Transfer Protocol (HTTP). Wenn Sie auf einer Webseite auf einen Link klicken, ein Formular absenden oder eine Suche ausführen, sendet der Browser eine HTTP-Anfrage an den Server.
Diese Anfrage enthält:
-
Eine URL, die den Zielserver und die Ressource identifiziert (zum Beispiel eine HTML-Datei, einen bestimmten Datenpunkt auf dem Server oder ein Werkzeug, das ausgeführt werden soll).
-
Eine Methode, die die erforderliche Aktion definiert (z.B., eine Datei zu holen oder einige Daten zu speichern oder zu aktualisieren). Die verschiedenen Methoden/Verben und ihre zugehörigen Aktionen sind unten aufgelistet:
GET: Eine spezifische Ressource erhalten (z.B., eine HTML-Datei, die Informationen über ein Produkt enthält, oder eine Liste von Produkten).POST: Eine neue Ressource erstellen (z.B., einen neuen Artikel zu einem Wiki hinzufügen, einen neuen Kontakt zu einer Datenbank hinzufügen).HEAD: Die Metadateninformationen über eine spezifische Ressource erhalten, ohne den Body abzurufen, wie esGETtun würde. Sie könnten z.B. eineHEAD-Anfrage verwenden, um herauszufinden, wann eine Ressource zuletzt aktualisiert wurde, und dann nur die (kostenintensivere)GET-Anfrage verwenden, um die Ressource herunterzuladen, falls sie sich geändert hat.PUT: Eine bestehende Ressource aktualisieren (oder eine neue erstellen, falls sie nicht vorhanden ist).DELETE: Die angegebene Ressource löschen.TRACE,OPTIONS,CONNECT,PATCH: Diese Verben sind für weniger häufige/fortgeschrittene Aufgaben gedacht, daher werden wir sie hier nicht behandeln.
-
Zusätzliche Informationen können mit der Anfrage codiert werden (z.B. HTML-Formulardaten). Informationen können folgendermaßen codiert sein:
- URL-Parameter:
GET-Anfragen kodieren Daten in der URL, die zum Server gesendet wird, indem Name/Wert-Paare an das Ende hinzugefügt werden — z.B.http://example.com?name=Fred&age=11. Sie haben immer ein Fragezeichen (?), das den Rest der URL von den URL-Parametern trennt, ein Gleichheitszeichen (=), das jeden Namen von seinem zugehörigen Wert trennt, und ein Kaufmanns-Und (&), das jedes Paar trennt. URL-Parameter sind von Natur aus "unsicher", da sie von Benutzern geändert und dann erneut gesendet werden können. Daher werden URL-Parameter/GET-Anfragen nicht für Anfragen verwendet, die Daten auf dem Server aktualisieren. POST-Daten.POST-Anfragen fügen neue Ressourcen hinzu, deren Daten innerhalb des Anfragenkörpers codiert sind.- Clientseitige Cookies. Cookies enthalten Sitzungsdaten über den Client, inklusive Schlüssel, die der Server nutzen kann, um ihren Anmeldestatus und Berechtigungen/Zugriffe auf Ressourcen zu bestimmen.
- URL-Parameter:
Webserver warten auf Client-Anforderungsnachrichten, verarbeiten sie, wenn sie eintreffen, und antworten dem Webbrowser mit einer HTTP-Antwortnachricht. Die Antwort enthält einen HTTP-Antwortstatuscode, der angibt, ob die Anfrage erfolgreich war (zum Beispiel 200 OK für Erfolg, 404 Not Found, wenn die Ressource nicht gefunden werden kann, 403 Forbidden, wenn der Benutzer nicht berechtigt ist, die Ressource zu sehen, usw.). Der Body der Antwort auf eine erfolgreiche GET-Anfrage enthält die angeforderte Ressource.
Wenn eine HTML-Seite zurückgegeben wird, wird sie vom Webbrowser gerendert. Als Teil der Verarbeitung kann der Browser Links zu anderen Ressourcen entdecken (z.B. verweist eine HTML-Seite üblicherweise auf JavaScript- und CSS-Dateien) und wird separate HTTP-Anfragen senden, um diese Dateien herunterzuladen.
Sowohl statische als auch dynamische Websites (wie in den folgenden Abschnitten behandelt) verwenden exakt dasselbe Kommunikationsprotokoll/-muster.
Beispiel einer GET-Anfrage/-Antwort
Sie können eine einfache GET-Anfrage stellen, indem Sie auf einen Link klicken oder auf einer Seite (wie einer Startseite einer Suchmaschine) suchen. Zum Beispiel sieht die HTTP-Anfrage, die gesendet wird, wenn Sie auf MDN nach dem Begriff "Client-Server-Übersicht" suchen, ähnlich dem unten gezeigten Text aus (sie wird nicht identisch sein, da Teile der Nachricht von Ihrem Browser/Setup abhängen).
Hinweis: Das Format von HTTP-Nachrichten ist in einem "Webstandard" (RFC9110) definiert. Sie müssen diese Ebene im Detail nicht kennen, aber zumindest wissen Sie jetzt, woher das alles kommt!
Die Anfrage
Jede Zeile der Anfrage enthält Informationen darüber. Der erste Teil wird als Header bezeichnet und enthält nützliche Informationen über die Anfrage, ähnlich wie ein HTML-Kopf nützliche Informationen über ein HTML-Dokument enthält (aber nicht den eigentlichen Inhalt, der sich im Body befindet):
GET /en-US/search?q=client+server+overview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev HTTP/1.1
Host: developer.mozilla.org
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: https://developer.mozilla.org/en-US/
Accept-Encoding: gzip, deflate, sdch, br
Accept-Language: en-US,en;q=0.8,es;q=0.6
Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _gat=1; _ga=GA1.2.1688886003.1471911953; ffo=true
Die erste und zweite Zeile enthalten die meisten der oben erwähnten Informationen:
- Die Art der Anfrage (
GET). - Die Zielressourcen-URL (
/en-US/search). - Die URL-Parameter (
q=client%2Bserver%2Boverview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev). - Die Ziel-/Host-Website (developer.mozilla.org).
- Das Ende der ersten Zeile enthält auch eine kurze Zeichenkette, die die spezifische Protokollversion identifiziert (
HTTP/1.1).
Die letzte Zeile enthält Informationen über die clientseitigen Cookies — Sie können in diesem Fall sehen, dass das Cookie eine ID zur Sitzungsverwaltung umfasst (Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; …).
Die übrigen Zeilen enthalten Informationen über den verwendeten Browser und die Arten von Antworten, die er verarbeiten kann. Zum Beispiel können Sie hier sehen, dass:
- Mein Browser (
User-Agent) Mozilla Firefox ist (Mozilla/5.0). - Er kann gzip-komprimierte Informationen akzeptieren (
Accept-Encoding: gzip). - Er kann die angegebenen Sprachen akzeptieren (
Accept-Language: en-US,en;q=0.8,es;q=0.6). - Die
Referer-Zeile zeigt die Adresse der Webseite an, die den Link zu dieser Ressource enthielt (d.h. den Ursprung der Anfrage,https://developer.mozilla.org/en-US/).
HTTP-Anfragen können auch einen Body besitzen, aber dieser ist in diesem Fall leer.
Die Antwort
Der erste Teil der Antwort auf diese Anfrage ist unten gezeigt. Der Header enthält Informationen wie die folgenden:
- Die erste Zeile umfasst den Antwortcode
200 OK, was uns sagt, dass die Anfrage erfolgreich war. - Wir können sehen, dass die Antwort im
text/html-Format ist (Content-Type). - Wir können auch sehen, dass es den UTF-8-Zeichensatz verwendet (
Content-Type: text/html; charset=utf-8). - Der Header gibt uns auch die Größe an (
Content-Length: 41823).
Am Ende der Nachricht sehen wir den Body-Inhalt — welcher das eigentliche HTML enthält, das durch die Anfrage zurückgegeben wurde.
HTTP/1.1 200 OK
Server: Apache
X-Backend-Server: developer1.webapp.scl3.mozilla.com
Vary: Accept, Cookie, Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:11:31 GMT
Keep-Alive: timeout=5, max=999
Connection: Keep-Alive
X-Frame-Options: DENY
Allow: GET
X-Cache-Info: caching
Content-Length: 41823
<!doctype html>
<html lang="en-US" dir="ltr" class="redesign no-js" data-ffo-opensanslight=false data-ffo-opensans=false >
<head prefix="og: http://ogp.me/ns#">
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<script>(function(d) { d.className = d.className.replace(/\bno-js/, ''); })(document.documentElement);</script>
…
Der Rest des Antwort-Headers umfasst Informationen über die Antwort (z.B., wann sie generiert wurde), den Server, und wie er erwartet, dass der Browser die Seite behandelt (z.B., die Zeile X-Frame-Options: DENY sagt dem Browser, dass diese Seite nicht in einem <iframe> in einer anderen Seite eingebettet werden darf).
Beispiel einer POST-Anfrage/-Antwort
Eine HTTP-POST-Anfrage wird durchgeführt, wenn Sie ein Formular übermitteln, das Informationen enthält, die auf dem Server gespeichert werden sollen.
Die Anfrage
Der untenstehende Text zeigt die HTTP-Anfrage, die gemacht wird, wenn ein Benutzer neue Profildetails auf dieser Seite einreicht. Das Format der Anfrage ist fast dasselbe wie im vorherigen GET-Anfragebeispiel, obwohl die erste Zeile diese Anfrage als POST identifiziert.
POST /en-US/profiles/hamishwillee/edit HTTP/1.1
Host: developer.mozilla.org
Connection: keep-alive
Content-Length: 432
Pragma: no-cache
Cache-Control: no-cache
Origin: https://developer.mozilla.org
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: https://developer.mozilla.org/en-US/profiles/hamishwillee/edit
Accept-Encoding: gzip, deflate, br
Accept-Language: en-US,en;q=0.8,es;q=0.6
Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; _gat=1; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _ga=GA1.2.1688886003.1471911953; ffo=true
csrfmiddlewaretoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT&user-username=hamishwillee&user-fullname=Hamish+Willee&user-title=&user-organization=&user-location=Australia&user-locale=en-US&user-timezone=Australia%2FMelbourne&user-irc_nickname=&user-interests=&user-expertise=&user-twitter_url=&user-stackoverflow_url=&user-linkedin_url=&user-mozillians_url=&user-facebook_url=
Der Hauptunterschied besteht darin, dass die URL keine Parameter hat. Wie Sie sehen, sind die Informationen aus dem Formular im Body der Anfrage kodiert (zum Beispiel wird der neue Benutzer-Vollname mit &user-fullname=Hamish+Willee gesetzt).
Die Antwort
Die Antwort auf die Anfrage ist unten gezeigt. Der Statuscode 302 Found teilt dem Browser mit, dass der Post erfolgreich war und dass er eine zweite HTTP-Anfrage stellen muss, um die im Location-Feld angegebene Seite zu laden. Die Informationen sind ansonsten ähnlich wie die der Antwort auf eine GET-Anfrage.
HTTP/1.1 302 FOUND
Server: Apache
X-Backend-Server: developer3.webapp.scl3.mozilla.com
Vary: Cookie
Vary: Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:38:13 GMT
Location: https://developer.mozilla.org/en-US/profiles/hamishwillee
Keep-Alive: timeout=5, max=1000
Connection: Keep-Alive
X-Frame-Options: DENY
X-Cache-Info: not cacheable; request wasn't a GET or HEAD
Content-Length: 0
Hinweis: Die in diesen Beispielen gezeigten HTTP-Antworten und -Anfragen wurden mit der Anwendung Fiddler erfasst, aber Sie können ähnliche Informationen mit Web-Schnüfflern (z.B. WebSniffer) oder Paketanalysatoren wie Wireshark erhalten. Sie können dies selbst ausprobieren. Verwenden Sie eines der verlinkten Tools und navigieren Sie dann durch eine Seite und bearbeiten Sie Profildaten, um die verschiedenen Anfragen und Antworten zu sehen. Die meisten modernen Browser haben auch Werkzeuge, die Netzwerk-Anfragen überwachen (zum Beispiel das Netzwerk-Monitor-Tool in Firefox).
Statische Seiten
Eine statische Seite ist eine, die immer denselben fest codierten Inhalt vom Server zurückgibt, wann immer eine bestimmte Ressource angefordert wird. Wenn Sie zum Beispiel eine Seite über ein Produkt unter /static/my-product1.html haben, wird diese Seite jedem Benutzer zurückgegeben. Wenn Sie ein weiteres ähnliches Produkt zu Ihrer Seite hinzufügen, müssen Sie eine weitere Seite hinzufügen (z.B. my-product2.html) und so weiter. Dies kann wirklich ineffizient werden — was passiert, wenn Sie zu Tausenden von Produktseiten kommen? Sie würden viel Code über jede Seite hinweg wiederholen (das grundlegende Seitentemplate, die Struktur usw.), und wenn Sie etwas an der Seitenstruktur ändern möchten — wie zum Beispiel einen neuen Abschnitt "Verwandte Produkte" hinzufügen — dann müssten Sie jede Seite einzeln ändern.
Hinweis: Statische Seiten sind ausgezeichnet, wenn Sie eine geringe Anzahl von Seiten haben und denselben Inhalt an jeden Benutzer senden wollen. Sie können jedoch erhebliche Wartungskosten verursachen, wenn die Anzahl der Seiten größer wird.
Lassen Sie uns rekapitulieren, wie dies funktioniert, indem wir erneut das Architekturdiagramm der statischen Seite betrachten, das wir im letzten Artikel betrachtet haben.
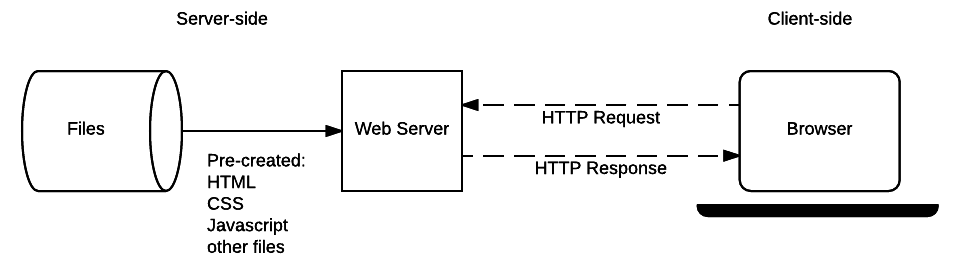
Wenn ein Benutzer zu einer Seite navigieren möchte, sendet der Browser eine HTTP-GET-Anfrage mit der URL seiner HTML-Seite. Der Server ruft das angeforderte Dokument aus seinem Dateisystem ab und gibt eine HTTP-Antwort zurück, die das Dokument und einen HTTP-Antwortstatuscode von 200 OK enthält (was Erfolg anzeigt). Der Server kann einen anderen Statuscode zurückgeben, zum Beispiel 404 Not Found, wenn die Datei nicht auf dem Server vorhanden ist, oder 301 Moved Permanently, wenn die Datei existiert, aber an einen anderen Ort umgeleitet wurde.
Der Server für eine statische Seite muss nur GET-Anfragen verarbeiten, da der Server keine modifizierbaren Daten speichert. Er ändert auch seine Antworten nicht anhand von HTTP-Anfragedaten (z.B. URL-Parameter oder Cookies).
Das Verständnis, wie statische Sites funktionieren, ist dennoch nützlich beim Erlernen der serverseitigen Programmierung, da dynamische Sites Anfragen für statische Dateien (CSS, JavaScript, statische Bilder usw.) genau auf die gleiche Weise behandeln.
Dynamische Seiten
Eine dynamische Seite ist eine, die Inhalte basierend auf der spezifischen Anforderungs-URL und den Daten generieren und zurückgeben kann (anstelle immer dieselbe fest codierte Datei für eine bestimmte URL zurückzugeben). Anhand des Beispiels einer Produktwebsite würde der Server Produkt„daten“ in einer Datenbank statt in einzelnen HTML-Dateien speichern. Wenn er eine HTTP-GET-Anfrage für ein Produkt erhält, bestimmt der Server die Produkt-ID, ruft die Daten aus der Datenbank ab und erstellt dann die HTML-Seite für die Antwort, indem er die Daten in eine HTML-Vorlage einfügt. Dies hat gegenüber einer statischen Site enorme Vorteile:
Durch die Verwendung einer Datenbank kann die Produktinformation effizient auf eine leicht erweiterbare, modifizierbare und durchsuchbare Weise gespeichert werden.
Durch die Verwendung von HTML-Vorlagen wird es sehr einfach, die HTML-Struktur zu ändern, denn dies muss nur an einer Stelle in einer einzigen Vorlage und nicht auf potenziell Tausenden von statischen Seiten getan werden.
Anatomie einer dynamischen Anfrage
Dieser Abschnitt bietet einen Schritt-für-Schritt-Überblick über den "dynamischen" HTTP-Anfrage- und Antwortzyklus, der aufbaut auf dem, was wir im letzten Artikel betrachtet haben, jedoch mit viel mehr Details. Um "die Dinge real zu halten", verwenden wir den Kontext einer Website für Sportmannschaftsmanager, auf der ein Trainer seinen Teamnamen und die Teamgröße in einem HTML-Formular auswählen und eine empfohlene "beste Aufstellung" für ihr nächstes Spiel erhalten kann.
Das Diagramm unten zeigt die Hauptelemente der "Team-Coach"-Website, zusammen mit Nummern für die Reihenfolge der Operationen, wenn der Trainer auf seine "beste Mannschafts"-Liste zugreift. Die Teile der Website, die sie dynamisch machen, sind die Webanwendung (so bezeichnen wir den serverseitigen Code, der HTTP-Anfragen verarbeitet und HTTP-Antworten zurückgibt), die Datenbank, die Informationen über Spieler, Teams, Trainer und deren Beziehungen enthält, und die HTML-Vorlagen.
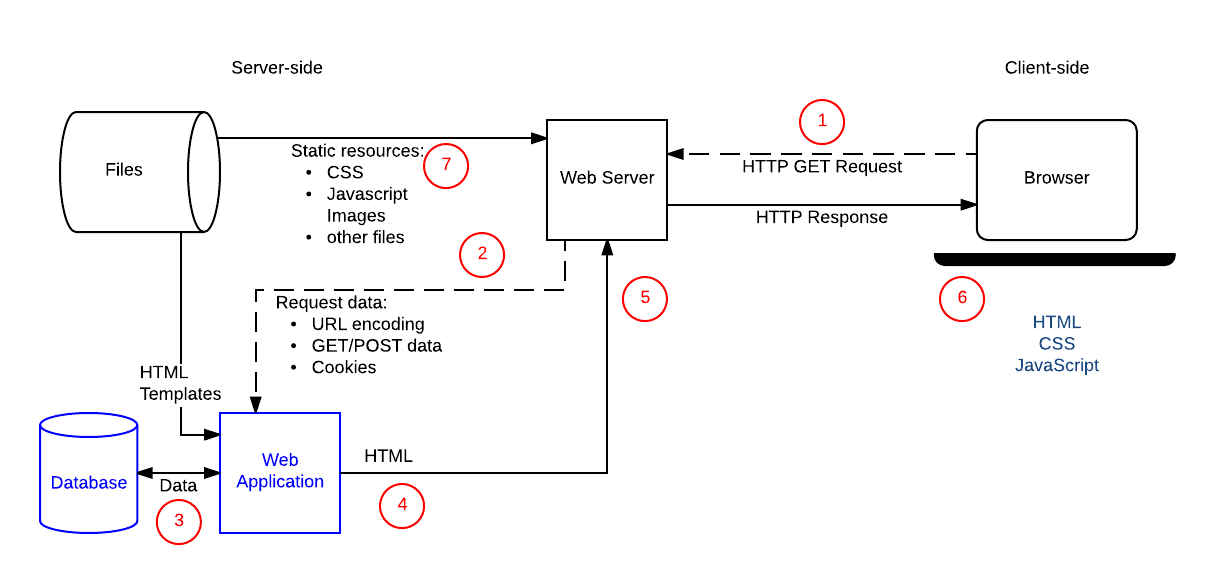
Nachdem der Trainer das Formular mit dem Teamnamen und der Spieleranzahl eingereicht hat, erfolgt der Ablauf der Operationen:
- Der Webbrowser erstellt eine HTTP-
GET-Anfrage an den Server mit der Basis-URL für die Ressource (/best) und codiert das Team und die Spieleranzahl entweder als URL-Parameter (z.B./best?team=my_team_name&show=11) oder als Teil des URL-Musters (z.B./best/my_team_name/11/). EineGET-Anfrage wird verwendet, da die Anfrage nur Daten abruft (nicht Daten modifiziert). - Der Webserver erkennt, dass die Anfrage "dynamisch" ist, und leitet sie zur Verarbeitung an die Webanwendung weiter (der Webserver bestimmt, wie er verschiedene URLs behandelt, basierend auf Mustermatching-Regeln, die in seiner Konfiguration definiert sind).
- Die Webanwendung identifiziert, dass die Absicht der Anfrage darin besteht, die "beste Mannschaftsliste" basierend auf der URL (
/best/) zu erhalten, und ermittelt den erforderlichen Teamnamen und die Anzahl der Spieler aus der URL. Die Webanwendung erhält dann die erforderlichen Informationen aus der Datenbank (unter Verwendung zusätzlicher "interner" Parameter zur Definition, welche Spieler "am besten" sind, und holt möglicherweise auch die Identität des eingeloggten Trainers aus einem clientseitigen Cookie). - Die Webanwendung erstellt dynamisch eine HTML-Seite, indem sie die Daten (aus der Datenbank) in Platzhalter innerhalb einer HTML-Vorlage einfügt.
- Die Webanwendung gibt das generierte HTML an den Webbrowser zurück (über den Webserver) zusammen mit einem HTTP-Statuscode von 200 ("Erfolg"). Sollte irgendetwas die Rückgabe des HTMLs verhindern, gibt die Webanwendung einen anderen Code zurück — zum Beispiel "404", um anzuzeigen, dass das Team nicht existiert.
- Der Webbrowser beginnt dann mit der Verarbeitung des zurückgegebenen HTMLs und sendet separate Anfragen, um alle anderen CSS- oder JavaScript-Dateien abzurufen, auf die es verweist (siehe Schritt 7).
- Der Webserver lädt statische Dateien aus dem Dateisystem und gibt sie direkt an den Browser zurück (korrekter Dateihandhabung basiert wieder auf der Konfiguration und Mustermatching von URLs).
Ein Vorgang zum Aktualisieren eines Datensatzes in der Datenbank würde ähnlich behandelt, außer dass wie jede Datenbankaktualisierung die HTTP-Anfrage vom Browser als POST-Anfrage codiert sein sollte.
Andere Arbeiten erledigen
Die Aufgabe einer Webanwendung besteht darin, HTTP-Anfragen zu empfangen und HTTP-Antworten zurückzugeben. Während die Interaktion mit einer Datenbank zum Abrufen oder Aktualisieren von Informationen sehr häufige Aufgaben sind, kann der Code gleichzeitig andere Dinge tun oder überhaupt nicht mit einer Datenbank interagieren.
Ein gutes Beispiel für eine zusätzliche Aufgabe, die eine Webanwendung ausführen könnte, wäre das Senden einer E-Mail an Benutzer, um deren Registrierung auf der Seite zu bestätigen. Die Seite könnte auch Logging oder andere Operationen ausführen.
Etwas anderes als HTML zurückgeben
Serverseitiger Website-Code muss nicht unbedingt HTML-Snippets/Dateien in der Antwort zurückgeben. Er kann stattdessen dynamisch erstellen und andere Dateitypen (Text, PDF, CSV usw.) oder sogar Daten (JSON, XML usw.) zurückgeben.
Dies ist besonders relevant für Websites, die durch das Abrufen von Inhalten vom Server mit JavaScript und das dynamische Aktualisieren der Seite arbeiten, anstatt immer eine neue Seite zu laden, wenn neuer Inhalt angezeigt werden soll. Siehe Netzwerkanfragen mit JavaScript durchführen für mehr über die Motivation für diesen Ansatz und wie dieses Modell aus Sicht des Clients aussieht.
Webframeworks vereinfachen serverseitige Webprogrammierung
Serverseitige Webframeworks erleichtern das Schreiben von Code zur Bearbeitung der oben beschriebenen Operationen erheblich.
Eine der wichtigsten Operationen, die sie ausführen, ist das Bereitstellen einfacher Mechanismen, um URLs für verschiedene Ressourcen/Seiten spezifischen Handler-Funktionen zuzuordnen. Dies macht es einfacher, den mit jedem Ressourcentyp verbundenen Code getrennt zu halten. Es hat auch Vorteile in Bezug auf Wartung, da Sie die URL, die zur Bereitstellung eines bestimmten Features verwendet wird, an einer Stelle ändern können, ohne die Handler-Funktion ändern zu müssen.
Zum Beispiel betrachten Sie den folgenden Django (Python)-Code, der zwei URL-Muster zwei View-Funktionen zuordnet. Das erste Muster stellt sicher, dass eine HTTP-Anfrage mit einer Ressourcen-URL von /best an eine Funktion namens index() im views-Modul weitergeleitet wird. Eine Anfrage, die das Muster /best/junior hat, wird stattdessen an die junior()-View-Funktion weitergeleitet.
# file: best/urls.py
#
from django.conf.urls import url
from . import views
urlpatterns = [
# example: /best/
url(r'^$', views.index),
# example: /best/junior/
url(r'^junior/$', views.junior),
]
Hinweis:
Die ersten Parameter in den url()-Funktionen mögen seltsam aussehen (z.B. r'^junior/$'), weil sie eine Mustermatching-Technik namens "reguläre Ausdrücke" (RegEx oder RE) verwenden. Sie müssen nicht wissen, wie reguläre Ausdrücke funktionieren, außer dass sie es uns ermöglichen, Muster in der URL zu matchen (anstelle der oben fest kodierten Werte) und sie als Parameter in unseren View-Funktionen zu verwenden. Ein wirklich einfaches RegEx könnte zum Beispiel "ein einzelner Großbuchstabe, gefolgt von 4 bis 7 Kleinbuchstaben" sagen.
Das Webframework erleichtert es auch, dass eine View-Funktion Informationen aus der Datenbank abruft. Die Struktur unserer Daten wird in Modellen definiert, bei denen es sich um Python-Klassen handelt, die die in der zugrunde liegenden Datenbank zu speichernden Felder definieren. Wenn wir ein Modell namens Team mit einem Feld namens "team_type" haben, können wir eine einfache Abfragesyntax verwenden, um alle Teams zurückzubekommen, die einen bestimmten Typ haben.
Das folgende Beispiel erhält eine Liste aller Teams, die den genauen (Groß- und Kleinschreibung) team_type von "junior" haben — beachten Sie das Format: Feldname (team_type) gefolgt von doppeltem Unterstrich, und dann den Typ des Matches, den Sie verwenden möchten (in diesem Fall exact). Es gibt viele andere Arten von Matches und wir können sie verketten. Wir können auch die Reihenfolge und die Anzahl der zurückgegebenen Ergebnisse steuern.
#best/views.py
from django.shortcuts import render
from .models import Team
def junior(request):
list_teams = Team.objects.filter(team_type__exact="junior")
context = {'list': list_teams}
return render(request, 'best/index.html', context)
Nachdem die junior()-Funktion die Liste der Junior-Teams erhalten hat, ruft sie die render()-Funktion auf, übergibt den originalen HttpRequest, eine HTML-Vorlage, und ein "Kontext"-Objekt, das die in der Vorlage enthaltenen Informationen definiert. Die render()-Funktion ist eine Komfortfunktion, die HTML mit einem Kontext und einer HTML-Vorlage generiert und es in einem HttpResponse-Objekt zurückgibt.
Natürlich können Sie mit Webframeworks auch viele andere Aufgaben leichter erledigen. Wir diskutieren viele weitere Vorteile und einige beliebte Webframework-Auswahlen im nächsten Artikel.
Zusammenfassung
An diesem Punkt sollten Sie einen guten Überblick über die Operationen haben, die serverseitiger Code ausführen muss, und einige der Möglichkeiten kennen, wie ein serverseitiges Webframework dies erleichtern kann.
In einem folgenden Modul werden wir Ihnen helfen, das beste Webframework für Ihre erste Seite auszuwählen.