Express Tutorial Teil 7: Deployment in die Produktion
Nachdem Sie nun eine Beispiel-Website mit Express erstellt und getestet haben, ist es an der Zeit, diese auf einem Webserver bereitzustellen, damit sie über das öffentliche Internet zugänglich ist. Diese Seite erklärt, wie man ein Express-Projekt hostet und umreißt, was Sie tun müssen, um es für die Produktion vorzubereiten.
| Voraussetzungen: | Schließen Sie alle vorherigen Themen des Tutorials ab, einschließlich Express-Tutorial Teil 6: Arbeiten mit Formularen. |
|---|---|
| Ziel: | Zu lernen, wo und wie Sie eine Express-App in die Produktion überführen können. |
Überblick
Sobald Ihre Website fertig ist (oder "genug" fertig ist, um öffentlicher Tests zu starten), müssen Sie sie irgendwo hosten, das öffentlicher und zugänglicher ist als Ihr persönlicher Entwicklungscomputer.
Bis jetzt haben Sie in einer Entwicklungsumgebung gearbeitet und Express/Node als Webserver verwendet, um Ihre Site im lokalen Browser/Netzwerk zu teilen und Ihre Website mit (unsicheren) Entwicklungseinstellungen zu betreiben, die Debugging und andere private Informationen freigeben. Bevor Sie eine Website extern hosten können, müssen Sie zuerst:
- Eine Umgebung für das Hosting der Express-App auswählen.
- Einige Änderungen an Ihren Projekteinstellungen vornehmen.
- Eine produktionsfähige Infrastruktur für das Servieren Ihrer Website einrichten.
Dieses Tutorial bietet einige Hinweise zu Ihren Optionen bei der Auswahl einer Hosting-Site, einen kurzen Überblick darüber, was Sie tun müssen, um Ihre Express-App für die Produktion bereitzumachen, und ein funktionierendes Beispiel dafür, wie Sie die LocalLibrary-Website auf dem Railway Cloud-Hosting-Service installieren.
Was ist eine Produktionsumgebung?
Die Produktionsumgebung ist die Umgebung, die vom Serverrechner bereitgestellt wird, auf der Ihre Website zur externen Nutzung ausgeführt wird. Die Umgebung umfasst:
- Computer-Hardware, auf der die Website läuft.
- Betriebssystem (z. B. Linux oder Windows).
- Runtime Ihrer Programmiersprache und Framework-Bibliotheken, auf denen Ihre Website geschrieben ist.
- Webserver-Infrastruktur, möglicherweise einschließlich eines Webservers, eines Reverse-Proxys, eines Lastenausgleichs usw.
- Datenbanken, auf die Ihre Website angewiesen ist.
Der Server könnte sich auf Ihrem Gelände befinden und über eine schnelle Verbindung mit dem Internet verbunden sein, aber es ist weitaus häufiger, einen Rechner zu verwenden, der "in der Cloud" gehostet wird. Das bedeutet, dass Ihr Code auf einem Remote-Computer (oder möglicherweise einem "virtuellen" Computer) im Rechenzentrum Ihres Hosting-Unternehmens ausgeführt wird. Der Remote-Server bietet in der Regel ein garantiertes Maß an Rechenressourcen (z. B. CPU, RAM, Speicherspeicher usw.) und Internetkonnektivität für einen bestimmten Preis.
Diese Art von fernzugänglicher Computer-/Netzwerk-Hardware wird als Infrastructure as a Service (IaaS) bezeichnet. Viele IaaS-Anbieter bieten Optionen zum Vorinstallieren eines bestimmten Betriebssystems an, auf dem Sie dann die anderen Komponenten Ihrer Produktionsumgebung installieren müssen. Andere Anbieter erlauben es Ihnen, vollständigere Umgebungen auszuwählen, vielleicht einschließlich einer kompletten Node-Einrichtung.
Hinweis: Vorgefertigte Umgebungen können die Einrichtung Ihrer Website sehr einfach machen, da sie die Konfiguration reduzieren, aber die verfügbaren Optionen können Sie auf einen unbekannten Server (oder andere Komponenten) beschränken und möglicherweise auf einer älteren Version des Betriebssystems basieren. Oftmals ist es besser, die Komponenten selbst zu installieren, damit Sie die gewünschten erhalten und wissen, wo Sie beginnen können, wenn Sie das System aufrüsten müssen!
Andere Hosting-Anbieter unterstützen Express als Teil eines Platform as a Service (PaaS)-Angebots. Bei dieser Art des Hostings müssen Sie sich nicht um den größten Teil Ihrer Produktionsumgebung kümmern (Server, Load Balancer usw.), da die Hostplattform diese für Sie übernimmt. Das macht die Bereitstellung recht einfach, da Sie sich nur auf Ihre Webanwendung konzentrieren müssen und nicht auf andere Server-Infrastruktur.
Einige Entwickler werden die Flexibilität von IaaS gegenüber PaaS bevorzugen, während andere den reduzierten Wartungsaufwand und das einfachere Skalieren von PaaS schätzen werden. Wenn Sie gerade erst anfangen, ist die Einrichtung Ihrer Website auf einem PaaS-System viel einfacher, daher werden wir dies in diesem Tutorial tun.
Hinweis: Wenn Sie sich für einen Node/Express-freundlichen Hosting-Anbieter entscheiden, sollte dieser Anweisungen bereitstellen, wie man eine Express-Website mit verschiedenen Konfigurationen von Webservern, Applikationsservern, Reverse-Proxies usw. einrichtet. Beispielsweise gibt es viele Schritt-für-Schritt-Anleitungen für verschiedene Konfigurationen in den DigitalOcean Node Community-Dokumentationen.
Auswahl eines Hosting-Anbieters
Es gibt zahlreiche Hosting-Anbieter, die entweder aktiv unterstützen oder gut mit Node (und Express) zusammenarbeiten. Diese Anbieter bieten verschiedene Arten von Umgebungen (IaaS, PaaS) sowie unterschiedliche Mengen an Computer- und Netzwerkressourcen zu unterschiedlichen Preisen.
Hinweis: Es gibt viele Hosting-Lösungen, und deren Dienste und Preise können sich mit der Zeit ändern. Während wir unten einige Optionen vorstellen, lohnt es sich, sowohl diese als auch andere Optionen zu überprüfen, bevor Sie sich für einen Hosting-Anbieter entscheiden.
Einige Dinge, die Sie beachten sollten, wenn Sie einen Host auswählen:
- Wie viel Traffic Ihre Website voraussichtlich haben wird und die Kosten für Daten- und Rechenressourcen, die erforderlich sind, um diese Nachfrage zu decken.
- Grad der Unterstützung für horizontales Skalieren (Hinzufügen weiterer Maschinen) und vertikales Skalieren (Upgrade auf leistungsfähigere Maschinen) und die Kosten dafür.
- Die Standorte, an denen der Anbieter Rechenzentren hat und daher wo der Zugriff wahrscheinlich am schnellsten ist.
- Die bisherige Leistung des Hosts in Bezug auf Betriebszeit und Ausfallzeiten.
- Tools zur Verwaltung der Website — sind sie einfach zu verwenden und sind sie sicher (z. B. SFTP vs. FTP)?
- Eingebaute Frameworks zur Überwachung Ihres Servers.
- Bekannte Einschränkungen. Einige Hosts blockieren absichtlich bestimmte Dienste (z. B. E-Mail). Andere bieten in einigen Preisklassen nur eine bestimmte Anzahl von „Live-Zeiten“ oder nur wenig Speicherplatz.
- Zusätzliche Vorteile. Einige Anbieter bieten kostenlose Domänennamen und Unterstützung für TLS-Zertifikate, für die Sie sonst bezahlen müssten.
- Ob der „kostenlose“ Tarif, auf den Sie sich verlassen, mit der Zeit ausläuft und ob die Kosten für den Wechsel zu einem teureren Tarif bedeuten, dass Sie besser von Anfang an einen anderen Dienst genutzt hätten!
Die gute Nachricht beim Einstieg ist, dass es recht viele Seiten gibt, die "kostenlose" Computerumgebungen zum Testen und Evaluieren bereitstellen. Diese sind meist recht ressourcenarme/limitierte Umgebungen und Sie sollten sich bewusst sein, dass sie nach einer Einführungszeit ablaufen oder andere Einschränkungen haben können. Sie eignen sich jedoch hervorragend zum Testen von Niedrig-Traffic-Sites in einer gehosteten Umgebung und bieten eine einfache Möglichkeit, bei höherem Traffic auf mehr Ressourcen umzusteigen. Beliebte Optionen in dieser Kategorie sind Glitch, Python Anywhere, Amazon Web Services, Microsoft Azure usw.
Die meisten Anbieter bieten auch einen „Basic“- oder „Hobby“-Tarif an, der für kleine Produktionsseiten gedacht ist und nützlichere Mengen an Rechenleistung und weniger Einschränkungen bietet. Railway, Heroku, DigitalOcean und Python Anywhere sind Beispiele für beliebte Hosting-Anbieter, die eine relativ kostengünstige Basiskomputingstufe (im Bereich von 5 bis 10 USD pro Monat) haben.
Hinweis: Denken Sie daran, dass der Preis nicht das einzige Auswahlkriterium ist. Wenn Ihre Website erfolgreich ist, kann sich herausstellen, dass die Skalierbarkeit die wichtigste Überlegung ist.
Ihre Website bereitstellen
Die wichtigsten Überlegungen bei der Veröffentlichung Ihrer Website betreffen die Websicherheit und die Leistung. Mindestens sollten Sie die Datenbankkonfiguration so ändern, dass Sie eine andere Datenbank für die Produktion verwenden und deren Anmeldeinformationen sichern können, die Stack-Traces von Fehlerseiten, die während der Entwicklung angezeigt werden, entfernen, Ihr Logging aufräumen und die entsprechenden Header setzen, um viele gängige Sicherheitsbedrohungen zu vermeiden.
In den folgenden Abschnitten skizzieren wir die wichtigsten Änderungen, die Sie an Ihrer App vornehmen sollten.
Hinweis: Weitere nützliche Tipps finden Sie in den Express-Dokumenten — siehe Produktions-Best-Practices: Leistung und Zuverlässigkeit und Produktions-Best-Practices: Sicherheit.
Datenbankkonfiguration
Bisher haben wir in diesem Tutorial eine einzige Entwicklungsdatenbank verwendet, deren Adresse und Anmeldedaten in app.js fest codiert sind. Da die Entwicklungsdatenbank keine Informationen enthält, deren Offenlegung oder Beschädigung wir fürchten, besteht kein besonderes Risiko, diese Details weiterzugeben. Wenn Sie jedoch mit echten Daten arbeiten, insbesondere mit persönlichen Informationen von Benutzern, dann ist es sehr wichtig, Ihre Datenbank-Anmeldeinformationen zu schützen.
Aus diesem Grund möchten wir für die Produktion eine andere Datenbank als für die Entwicklung verwenden und die Anmeldeinformationen der Produktionsdatenbank vom Quellcode getrennt halten, damit sie ordnungsgemäß geschützt werden können.
Wenn Ihr Hosting-Anbieter das Setzen von Umgebungsvariablen über eine Weboberfläche unterstützt (wie viele dies tun), besteht eine Möglichkeit darin, den Server die Datenbank-URL aus einer Umgebungsvariablen abrufen zu lassen. Unten verändern wir die LocalLibrary-Website, um die Datenbank-URI aus einer OS-Umgebungsvariablen zu beziehen, falls diese definiert wurde, ansonsten wird die Entwicklungsdatenbank-URL verwendet.
Öffnen Sie app.js und finden Sie die Zeile, die die MongoDB-Verbindungsvariable setzt. Es wird etwa so aussehen:
const mongoDB =
"mongodb+srv://your_user_name:[email protected]/local_library?retryWrites=true&w=majority";
Ersetzen Sie die Zeile durch den folgenden Code, der process.env.MONGODB_URI verwendet, um die Verbindungszeichenfolge aus einer Umgebungsvariablen namens MONGODB_URI zu erhalten, falls diese gesetzt wurde (verwenden Sie Ihre eigene Datenbank-URL anstelle des Platzhalters unten).
// Set up mongoose connection
const mongoose = require("mongoose");
mongoose.set("strictQuery", false);
const dev_db_url =
"mongodb+srv://your_user_name:[email protected]/local_library?retryWrites=true&w=majority";
const mongoDB = process.env.MONGODB_URI || dev_db_url;
main().catch((err) => console.log(err));
async function main() {
await mongoose.connect(mongoDB);
}
Hinweis:
Eine weitere häufige Methode, um Produktionsdatenbankanmeldinformationen vom Quellcode zu trennen, besteht darin, sie aus einer .env-Datei zu lesen, die separat im Dateisystem bereitgestellt wird (zum Beispiel könnten sie mit dem npm dotenv-Modul gelesen werden).
Setzen von NODE_ENV auf 'production'
Wir können Stack-Traces auf Fehlerseiten entfernen, indem wir die NODE_ENV-Umgebungsvariable auf production setzen (sie ist standardmäßig auf 'development' gesetzt). Neben dem Erzeugen weniger ausführlicher Fehlermeldungen, führt das Setzen der Variable auf production auch zum Caching von Ansichtsvorlagen und CSS-Dateien, die aus CSS-Erweiterungen generiert werden. Tests zeigen, dass das Setzen von NODE_ENV auf production die Leistung der App um das Drei- bis Vierfache verbessern kann!
Diese Änderung kann entweder durch die Verwendung von export, einer Umgebungsdatei oder des OS-Initialisierungssystems erfolgen.
Hinweis: Dies ist eigentlich eine Änderung, die Sie an Ihrer Umgebungseinrichtung vornehmen, nicht an Ihrer App, aber hier wichtig genug zu erwähnen! Wir zeigen, wie dies in unserem Hosting-Beispiel unten eingestellt wird.
Angemessenes Logging
Logging-Aufrufe können sich auf eine stark frequentierte Website auswirken. In einer Produktionsumgebung müssen Sie möglicherweise die Website-Aktivität protokollieren (z. B. nachverfolgen von Verkehr oder API-Aufrufen), aber Sie sollten versuchen, die Menge an Logging, die für Debugging-Zwecke hinzugefügt wird, zu minimieren.
Eine Möglichkeit, „Debug“-Protokollierung in der Produktion zu minimieren, ist die Verwendung eines Moduls wie debug, das es Ihnen ermöglicht, zu steuern, welche Protokollierung durchgeführt wird, indem Sie eine Umgebungsvariable setzen. Zum Beispiel zeigt das folgende Codefragment, wie Sie "author"-Protokollierung einrichten könnten. Die Debug-Variable wird mit dem Namen 'author' deklariert, und das Präfix „author“ wird automatisch für alle Logs dieses Objekts angezeigt.
const debug = require("debug")("author");
// Display Author update form on GET.
exports.author_update_get = asyncHandler(async (req, res, next) => {
const author = await Author.findById(req.params.id).exec();
if (author === null) {
// No results.
debug(`id not found on update: ${req.params.id}`);
const err = new Error("Author not found");
err.status = 404;
return next(err);
}
res.render("author_form", { title: "Update Author", author });
});
Sie können dann eine bestimmte Gruppe von Logs aktivieren, indem Sie sie als kommaseparierte Liste in der DEBUG-Umgebungsvariable angeben.
Sie können die Variablen so einstellen, dass Autoren- und Buchlogs angezeigt werden (es werden auch Wildcards unterstützt).
#Windows
set DEBUG=author,book
#Linux
export DEBUG="author,book"
Hinweis:
Aufrufe zu debug können die Protokollierung ersetzen, die Sie möglicherweise zuvor mit console.log() oder console.error() gemacht haben. Ersetzen Sie alle console.log()-Aufrufe in Ihrem Code durch Protokollierung über das debug-Modul. Schalten Sie das Logging in Ihrer Entwicklungsumgebung ein und aus, indem Sie die DEBUG-Variable setzen und beobachten Sie die Auswirkungen auf das Logging.
Wenn Sie Website-Aktivität protokollieren müssen, können Sie eine Protokollierungs-Bibliothek wie Winston oder Bunyan verwenden. Weitere Informationen zu diesem Thema finden Sie unter: Produktions-Best-Practices: Leistung und Zuverlässigkeit.
Verwenden von gzip/deflate-Komprimierung für Antworten
Webserver können oft die HTTP-Antwort an einen Client komprimieren, wodurch sich die Zeit erheblich verkürzt, die ein Client benötigt, um die Seite abzurufen und zu laden. Die verwendete Komprimierungsmethode hängt von den Dekomprimierungsmethoden ab, die der Client in der Anfrage angibt (die Antwort wird unkomprimiert geschickt, wenn keine Kompressionsmethoden unterstützt werden).
Fügen Sie dies ihrer Seite mit compression-Middleware hinzu. Installieren Sie dies im Hauptverzeichnis Ihres Projekts, indem Sie den folgenden Befehl ausführen:
npm install compression
Öffnen Sie ./app.js und binden Sie die Komprimierungsbibliothek wie gezeigt ein. Fügen Sie die Komprimierungsbibliothek mit der use()-Methode in die Middleware-Kette ein (dies sollte vor allen Routen erscheinen, die Sie komprimieren möchten - in diesem Fall alle!)
const catalogRouter = require("./routes/catalog"); // Import routes for "catalog" area of site
const compression = require("compression");
// Create the Express application object
const app = express();
// …
app.use(compression()); // Compress all routes
app.use(express.static(path.join(__dirname, "public")));
app.use("/", indexRouter);
app.use("/users", usersRouter);
app.use("/catalog", catalogRouter); // Add catalog routes to middleware chain.
// …
Hinweis: Für eine stark frequentierte Website in der Produktion würden Sie diese Middleware nicht verwenden. Stattdessen würden Sie einen Reverse Proxy wie Nginx verwenden.
Verwenden von Helmet, um gegen bekannte Schwachstellen zu schützen
Helmet ist ein Middleware-Paket. Es kann geeignete HTTP-Header setzen, die Ihre App vor bekannten Web-Schwachstellen schützen (siehe die Dokumentation für weitere Informationen darüber, welche Header es setzt und welche Schwachstellen es schützt).
Installieren Sie dies im Hauptverzeichnis Ihres Projekts, indem Sie den folgenden Befehl ausführen:
npm install helmet
Öffnen Sie ./app.js und binden Sie die helmet-Bibliothek wie gezeigt ein.
Dann fügen Sie das Modul mit der use()-Methode in die Middleware-Kette ein.
const compression = require("compression");
const helmet = require("helmet");
// Create the Express application object
const app = express();
// Add helmet to the middleware chain.
// Set CSP headers to allow our Bootstrap and jQuery to be served
app.use(
helmet.contentSecurityPolicy({
directives: {
"script-src": ["'self'", "code.jquery.com", "cdn.jsdelivr.net"],
},
}),
);
// …
Normalerweise hätten wir einfach app.use(helmet()); eingefügt, um die Teilmenge der sicherheitsrelevanten Header hinzuzufügen, die für die meisten Websites sinnvoll sind.
In der LocalLibrary-Basisvorlage haben wir jedoch einige Bootstrap- und jQuery-Skripte eingeschlossen.
Diese verstoßen gegen die Standard Content Security Policy (CSP) von Helmet, die das Laden von Skripten von anderen Seiten nicht erlaubt.
Um es diesen Skripten zu erlauben, brauchen wir die Helmet-Konfiguration so anpassen, dass es CSP-Direktiven setzt, die das Laden von Skripten von den angegebenen Domains erlauben.
Für Ihren eigenen Server können Sie je nach Bedarf spezifische Header hinzufügen/entfernen, indem Sie den Anweisungen für die Verwendung von Helmet hier folgen.
Hinzufügen von Rate Limiting zu den API-Routen
Express-rate-limit ist ein Middleware-Paket, das verwendet werden kann, um wiederholte Anforderungen an APIs und Endpunkte zu begrenzen. Es gibt viele Gründe, warum übermäßige Anfragen an Ihre Seite gestellt werden können, wie zum Beispiel Denial-of-Service-Attacken, Brute-Force-Attacken oder auch einfach nur ein Client oder Skript, das nicht wie erwartet funktioniert. Neben den Leistungsproblemen, die durch zu viele Anfragen verursacht werden können, wenn der Server langsamer wird, können Ihnen auch Gebühren für den zusätzlichen Traffic entstehen. Dieses Paket kann verwendet werden, um die Anzahl der Anfragen zu begrenzen, die an eine bestimmte Route oder eine Gruppe von Routen gesendet werden können.
Installieren Sie dies im Hauptverzeichnis Ihres Projekts, indem Sie den folgenden Befehl ausführen:
npm install express-rate-limit
Öffnen Sie ./app.js und binden Sie die express-rate-limit-Bibliothek wie gezeigt ein.
Dann fügen Sie das Modul mit der use()-Methode in die Middleware-Kette ein.
const compression = require("compression");
const helmet = require("helmet");
const RateLimit = require("express-rate-limit");
const app = express();
// Set up rate limiter: maximum of twenty requests per minute
const limiter = RateLimit({
windowMs: 1 * 60 * 1000, // 1 minute
max: 20,
});
// Apply rate limiter to all requests
app.use(limiter);
// …
Der oben ausgeführte Befehl begrenzt alle Anfragen auf 20 pro Minute (dies können Sie nach Bedarf ändern).
Hinweis: Drittanbieter-Dienste wie Cloudflare können ebenfalls verwendet werden, wenn Sie erweiterte Schutzmaßnahmen gegen Denial-of-Service- oder andere Arten von Angriffen benötigen.
Setzen der Node-Version
Für Node-Anwendungen, einschließlich Express, enthält die package.json-Datei alles, was ein Hosting-Anbieter braucht, um die Abhängigkeiten und die Einstiegsdatei der Anwendung zu ermitteln.
Das einzige fehlende wichtige Element in unserer aktuellen package.json ist die Version von Node, die von der Bibliothek benötigt wird. Sie können die während der Entwicklung verwendete Node-Version ermitteln, indem Sie den Befehl eingeben:
>node --version
v16.17.1
Öffnen Sie package.json und fügen Sie diese Information als engines > node hinzu, wie gezeigt (verwenden Sie die Versionsnummer Ihres Systems).
"engines": {
"node": ">=16.17.1"
},
Der Hosting-Service unterstützt möglicherweise nicht die spezifisch angegebene Node-Version, aber diese Änderung sollte sicherstellen, dass versucht wird, eine Version mit derselben Hauptversionsnummer oder einer neueren Version zu verwenden.
Beachten Sie, dass es möglicherweise andere Möglichkeiten gibt, die Node-Version auf verschiedenen Hosting-Services anzugeben, aber der package.json-Ansatz ist weit verbreitet.
Abhängigkeiten abrufen und erneut testen
Bevor wir fortfahren, sollten wir die Seite erneut testen und sicherstellen, dass sie durch keine unserer Änderungen beeinträchtigt wurde.
Zunächst müssen wir unsere Abhängigkeiten abrufen. Dazu können Sie den folgenden Befehl in Ihrem Terminal im Hauptverzeichnis des Projekts ausführen:
npm install
Führen Sie nun die Seite aus (siehe Testen der Routen für die relevanten Befehle) und überprüfen Sie, ob die Seite noch wie erwartet funktioniert.
Erstellen eines Anwendungsrepositorys auf GitHub
Viele Hosting-Services ermöglichen es Ihnen, Projekte von einem lokalen Repository oder von cloudbasierten Versionskontrollplattformen zu importieren und/oder zu synchronisieren. Dies kann die Bereitstellung und iterative Entwicklung erheblich erleichtern.
Für dieses Tutorial richten wir ein GitHub-Konto und -Repository für die Bibliothek ein und verwenden das git-Tool, um unseren Quellcode hochzuladen.
Hinweis: Sie können diesen Schritt überspringen, wenn Sie GitHub bereits zur Verwaltung Ihres Quellcodes verwenden!
Beachten Sie, dass die Verwendung von Versionskontrolltools gute Softwareentwicklungspraxis ist, da es Ihnen ermöglicht, Änderungen auszuprobieren und zwischen Ihren Experimenten und "bekannt gutem Code" zu wechseln, wenn Sie es benötigen!
Die Schritte sind:
-
Besuchen Sie https://github.com/ und erstellen Sie ein Konto.
-
Sobald Sie sich eingeloggt haben, klicken Sie auf den +-Link in der oberen Symbolleiste und wählen Sie New repository.
-
Füllen Sie alle Felder in diesem Formular aus. Obwohl diese nicht zwingend sind, werden sie dringend empfohlen.
- Geben Sie einen neuen Repository-Namen ein (z. B. express-locallibrary-tutorial), und eine Beschreibung (z. B. "Local Library-Website geschrieben in Express (Node)").
- Wählen Sie Node in der Add .gitignore-Auswahliste.
- Wählen Sie Ihre bevorzugte Lizenz in der Add license-Auswahliste.
- Aktivieren Sie Initialize this repository with a README.
Warnung: Die Standardzugriffseinstellung "Public" macht den gesamten Quellcode — einschließlich Ihres Datenbank-Benutzernamens und -Passworts — für jeden im Internet sichtbar! Stellen Sie sicher, dass der Quellcode Anmeldeinformationen nur aus Umgebungsvariablen liest und keine Anmeldeinformationen fest codiert.
Wenn das nicht der Fall ist, wählen Sie die Option "Private", um nur ausgewählten Personen den Zugang zum Quellcode zu ermöglichen.
-
Drücken Sie Create repository.
-
Klicken Sie auf die grüne Clone or download-Schaltfläche auf Ihrer neuen Repo-Seite.
-
Kopieren Sie die URL aus dem Textfeld im erscheinenden Dialogfeld. Wenn Sie den Repository-Namen "express-locallibrary-tutorial" verwendet haben, sollte die URL etwa so aussehen:
https://github.com/<your_git_user_id>/express-locallibrary-tutorial.git.
Jetzt, da das Repository ("Repo") auf GitHub erstellt wurde, möchten wir es auf unseren lokalen Computer klonen (kopieren):
-
Installieren Sie git für Ihren lokalen Computer (offizielle Git-Download-Anleitung).
-
Öffnen Sie ein Kommandozeilen- / Terminal-Fenster und klonen Sie Ihr Repo mit der oben kopierten URL:
bashgit clone https://github.com/<your_git_user_id>/express-locallibrary-tutorial.gitDadurch wird das Repository im aktuellen Verzeichnis erstellt.
-
Navigieren Sie in den Repo-Ordner.
bashcd express-locallibrary-tutorial
Kopieren Sie dann Ihre Anwendungsquelldateien in den Repo-Ordner, machen Sie diese Teil des Repos mit git und laden Sie sie auf GitHub hoch:
-
Kopieren Sie Ihre Express-Anwendung in diesen Ordner (ohne /node_modules, der Abhängigkeitsdateien enthält, die Sie bei Bedarf von npm abrufen sollten).
-
Öffnen Sie ein Kommandozeilen- / Terminal-Fenster und verwenden Sie den
add-Befehl, um alle Dateien zu git hinzuzufügen.bashgit add -A -
Verwenden Sie den
status-Befehl, um zu überprüfen, dass alle Dateien, die Siecommit-en wollen, korrekt sind (Sie möchten Quellcodedateien erreichen, nicht Binär- oder temporäre Dateien etc.). Es sollte etwa wie die folgende Auflistung aussehen.bashgit statusOn branch main Your branch is up-to-date with 'origin/main'. Changes to be committed: (use "git reset HEAD <file>..." to unstage) new file: ... -
Wenn Sie zufrieden sind,
commit-en Sie die Dateien zu Ihrem lokalen Repo. Dies entspricht dem Abschluss Ihrer Änderungen und dem Hinzufügen als offizieller Teil des lokalen Repos.bashgit commit -m "First version of application moved into GitHub" -
Zu diesem Zeitpunkt wurde das Remote-Repo noch nicht geändert. Der letzte Schritt ist, Ihr lokales Repo mit dem folgenden Befehl zum entfernten GitHub-Repo zu synchronisieren (
push):bashgit push origin main
Wenn dieser Vorgang abgeschlossen ist, sollten Sie in der Lage sein, auf die Seite auf GitHub zu gehen, auf der Sie Ihr Repo erstellt haben, die Seite neu zu laden und zu sehen, dass Ihre gesamte Anwendung nun hochgeladen wurde. Sie können Ihr Repo weiterhin aktualisieren, indem Sie diesen Zyklus aus add/commit/push verwenden, wenn sich Dateien ändern.
Dies ist ein guter Zeitpunkt, ein Backup Ihres "unveränderten" Projekts zu erstellen — während einige der Änderungen, die wir in den folgenden Abschnitten vornehmen werden, für die Bereitstellung auf jedem Hosting-Service nützlich sein könnten (oder für die Entwicklung), andere möglicherweise nicht.
Sie können dies mit git auf der Kommandozeile tun:
# Create branch vanilla_deployment from the current branch (main)
git checkout -b vanilla_deployment
# Push the new branch to GitHub
git push origin vanilla_deployment
# Switch back to main
git checkout main
# Make any further changes in a new branch
git pull upstream main # Merge the latest changes from GitHub
git checkout -b my_changes # Create a new branch
Hinweis: Git ist unglaublich mächtig! Um mehr zu erfahren, siehe Git lernen.
Beispiel: Hosting auf Glitch
Dieser Abschnitt bietet eine praktische Demonstration, wie man LocalLibrary auf Glitch hostet.
Warum Glitch?
Wir entscheiden uns, Glitch aus mehreren Gründen zu verwenden:
- Glitch hat einen kostenlosen Starterplan, der wirklich kostenlos ist, wenn auch mit einigen Einschränkungen. Dass es für alle Entwickler erschwinglich ist, ist für MDN wirklich wichtig!
- Glitch kümmert sich um die Infrastruktur, sodass Sie es nicht tun müssen. Sich nicht um Server, Load Balancer, Reverse Proxies und dergleichen kümmern zu müssen, macht es viel einfacher, anzufangen.
- Die Fähigkeiten und Konzepte, die Sie beim Verwenden von Glitch lernen, sind übertragbar.
- Die Einschränkungen des Dienstes und des Plans beeinträchtigen uns beim Verwenden von Glitch für das Tutorial nicht wirklich.
Beispielsweise:
- Der Starterplan bietet nur 1000 „Projekt-Stunden“ pro Monat, die monatlich zurückgesetzt werden. Dies wird verwendet, wenn Sie die Seite aktiv bearbeiten oder wenn jemand darauf zugreift. Wenn niemand die Seite bearbeitet oder darauf zugreift, wird sie eingeschläfert.
- Die Starterplan-Umgebung hat eine begrenzte Menge an RAM und Speicherplatz für Container. Für das Tutorial ist mehr als genug vorhanden, insbesondere da unsere Datenbank anderswo gehostet wird.
- Benutzerdefinierte Domains werden nicht gut unterstützt (zum Zeitpunkt des Schreibens).
- Weitere Einschränkungen finden Sie auf der Glitch technische Einschränkungen Seite.
Während Glitch für das Hosting dieser Demonstration geeignet ist, sollten Sie sich die Zeit nehmen zu bestimmen, ob es für Ihre eigene Website geeignet ist.
Wie funktioniert Glitch?
Glitch bietet eine webbasierte Schnittstelle, in der Sie Projekte aus Startervorlagen erstellen oder sie von GitHub importieren und dann die Projektdateien hinzufügen und bearbeiten können. Während Sie Änderungen vornehmen, wird das Projekt in seinem eigenen isolierten und unabhängigen virtualisierten Container erstellt und ausgeführt.
Wie das alles "unter der Haube" funktioniert, bleibt ein Geheimnis — Glitch sagt es nicht.
Klar ist jedoch, dass solange Sie eine ziemlich standardmäßige Node.js-Webanwendung erstellen (z. B. Verwendung von package.json für Ihre Abhängigkeiten) und nicht mehr Ressourcen verbrauchen als auf der technischen Einschränkungen Seite beschrieben, sollte Ihre Anwendung "einfach funktionieren".
Sobald die Anwendung läuft, kann sie für die Produktion unter Verwendung von privaten Daten, die in einer .env-Datei bereitgestellt werden, konfiguriert werden.
Die Werte in den geheimen Daten werden von der Anwendung als Umgebungsvariablen gelesen, wie Sie sich aus einem vorherigen Abschnitt erinnern werden, ist dies, wie wir unsere Anwendung konfiguriert haben, um seine Datenbank-URL zu beziehen.
Beachten Sie, dass die Variablen geheim sind: Die .env sollte nicht in Ihr GitHub-Repository aufgenommen werden.
Die Glitch-Bearbeitungsansicht bietet auch Terminal-Zugriff auf die Web-App-Umgebung an, die Sie verwenden können, um mit der Web-App zu arbeiten, als würde sie auf Ihrem lokalen Rechner laufen.
Das ist alles, was Sie an Übersicht brauchen, um loszulegen. Als nächstes richten wir ein Glitch-Konto ein, laden das Bibliotheksprojekt von GitHub hoch und verbinden es mit einer Datenbank.
Erhalten eines Glitch-Kontos
Um Glitch verwenden zu können, müssen Sie zunächst ein Konto erstellen:
- Gehen Sie zu glitch.com und klicken Sie auf die Sign up-Schaltfläche in der oberen Symbolleiste.
- Wählen Sie GitHub im Popup, um sich mit Ihren GitHub-Anmeldeinformationen anzumelden.
- Sie werden dann in das Glitch-Dashboard eingeloggt: https://glitch.com/dashboard.
Fehlerbehebung bei der Node.js-Version
Hosting-Anbieter unterstützen üblicherweise einige Hauptversionen der neuesten Node.js-Veröffentlichungen.
Wenn die genaue „kleinere“ Version, die Sie in Ihrer package.json-Datei angegeben haben, nicht unterstützt wird, weichen sie normalerweise auf die nächstgelegene Version aus, die sie unterstützen (und oft funktioniert dies einwandfrei).
Leider ist zum Zeitpunkt des Schreibens die höchste unterstützte Version auf Glitch Node.js 16.
Wenn Sie mit Node.js 17 oder später entwickelt haben, sollten Sie die in Ihrer package.json-Datei verwendete Version reduzieren, wie gezeigt.
Sie müssen auch erneut testen:
"engines": {
"node": ">=v16"
},
Glitch plant, Node.js zu aktualisieren und es in Zukunft besser aktuell zu halten — und vielleicht besteht zum Zeitpunkt, zu dem Sie dies lesen, diese Versionsbeschränkung nicht mehr.
Statt die node-Version herunterzustufen, könnten Sie Ihr Projekt hochladen, um zu sehen, ob es gebaut wird.
Sollten Fehler auftreten und Ihre Anwendung nicht geladen werden, sollten Sie versuchen, die node-Version auf >=v16 in Ihrer package.json in dem Glitch-Editor zu setzen.
Hinweis: Sie können die unterstützten Versionen auch überprüfen, indem Sie den folgenden Befehl in das Terminal eines beliebigen Glitch-Projekts eingeben:
ls -l /opt/nvm/versions/node | grep '^d' | awk '{ print $9 }'
Auf Glitch von GitHub aus bereitstellen
Als Nächstes importieren wir das Bibliotheksprojekt von GitHub. Wählen Sie zuerst die Option Dashboard aus dem oberen Menü der Seite und dann die New project-Schaltfläche. Glitch zeigt eine Liste von Optionen für das neue Projekt an; wählen Sie Import from GitHub.
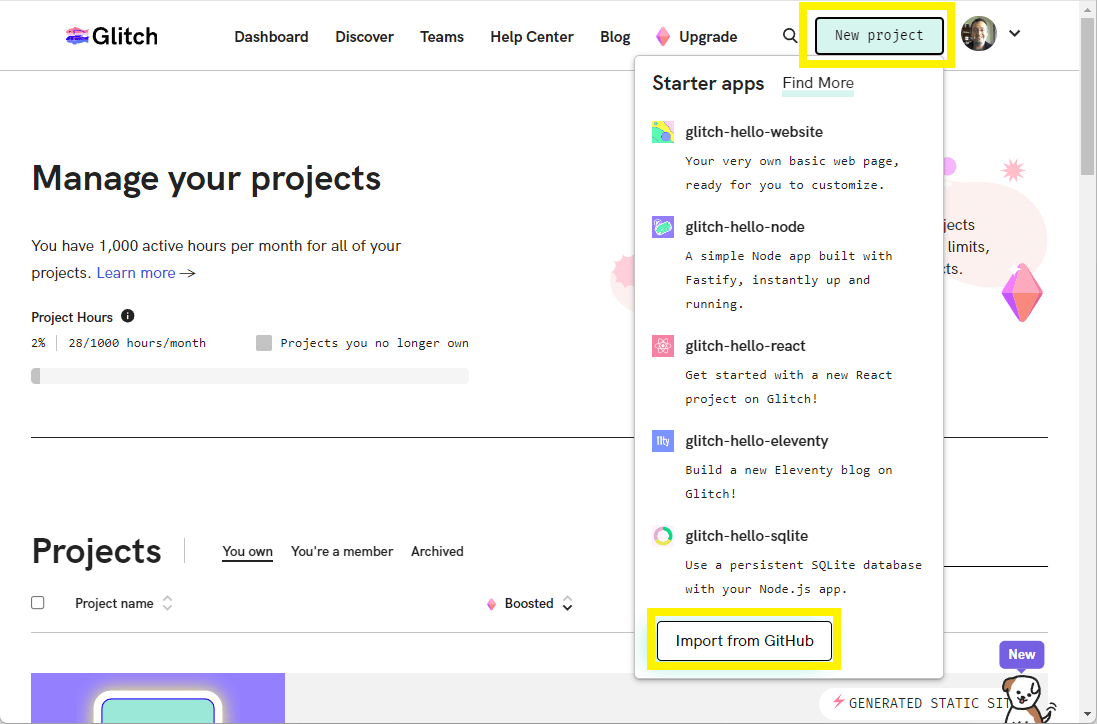
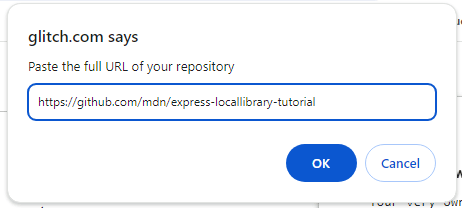
Es erscheint ein Popup. Geben Sie die URL Ihres GitHub-Bibliotheks-Repositorys in das Popup ein und drücken Sie OK. Unten haben wir das Repo für das bearbeitete Projekt eingegeben.
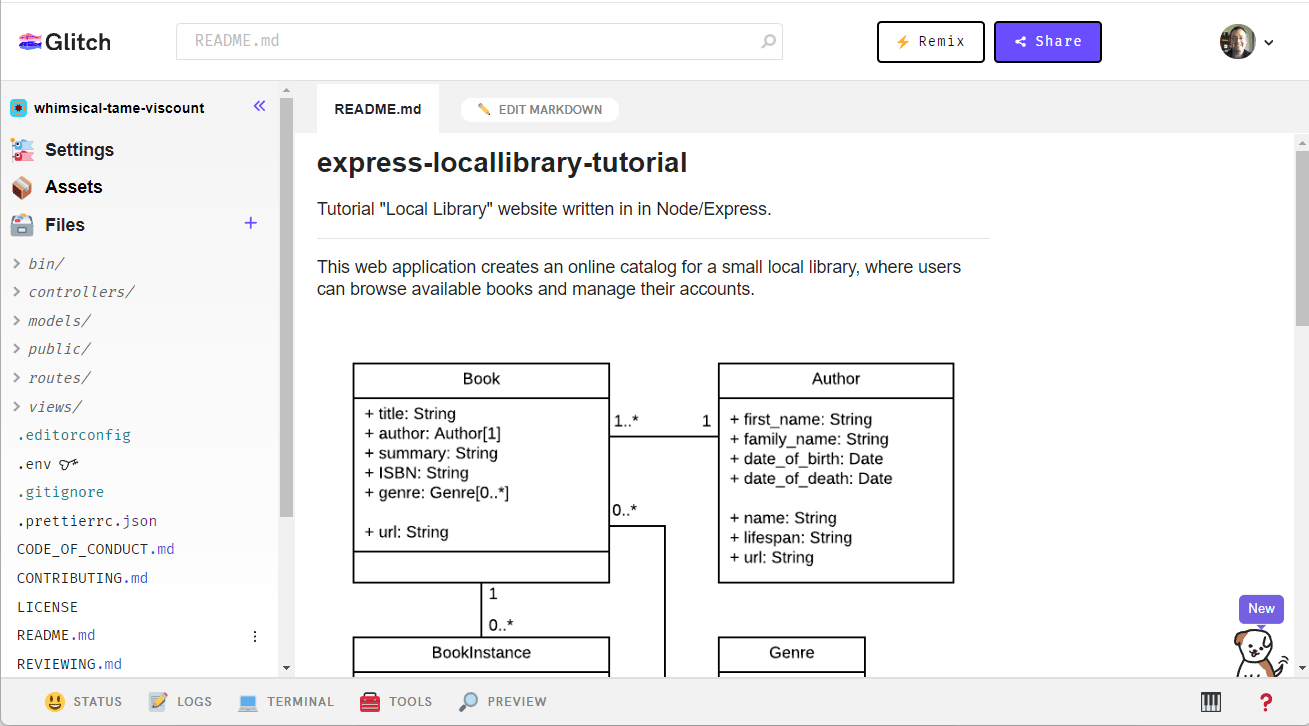
Glitch wird dann das Projekt importieren und Benachrichtigungen über den Fortschritt anzeigen. Nach Abschluss zeigt es die Bearbeitungsansicht für das neue Projekt an, wie unten gezeigt.
Sie können die URL der Live-Site erhalten, indem Sie die Share-Schaltfläche auswählen.
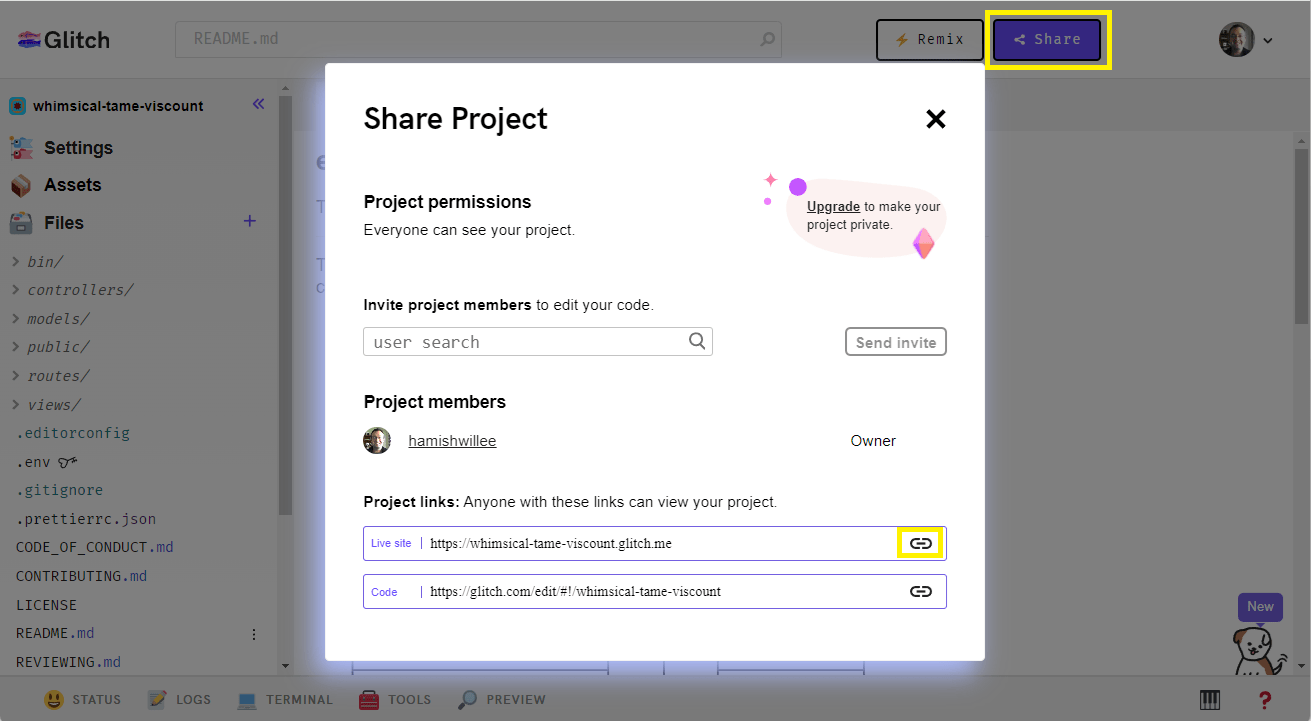
Öffnen Sie eine neue Browser-Registerkarte und kopieren Sie den Link der Live-Site in die Adressleiste. Die Local Library-Site sollte sich öffnen und Daten aus der Entwicklungsdatenbank anzeigen.
Hinweis: Dieser Vorgang war ein einmaliger Import von GitHub. Sie können auch GitHub-Aktionen wie glitch-project-sync verwenden, um Glitch und > Ihr Projekt synchron zu halten.
Verwenden einer Produktions-MongoDB-Datenbank
Sie sollten eine andere Datenbank für die Produktion als für die Entwicklung einrichten. Während Glitch nur SQLite-Datenbanken hostet (und wir sind auf die Verwendung von MongoDB eingerichtet), bieten viele andere Seiten MongoDB-Datenbanken als Service an.
Eine Option ist es, die Einrichtung der MongoDB-Datenbank-Anweisungen aus einem früheren Tutorial-Anleitungsabschnitt zu folgen, um eine neue Produktionsdatenbank einzurichten.
Um die Produktionsdatenbank für die Bibliotheksanwendung zugänglich zu machen, öffnen Sie die .env-Datei in der Editoransicht des Projekts.
Geben Sie die Datenbank-URL-Variable MONGODB_URI ein und die URL Ihrer Produktionsdatenbank.
Die Site wird aktualisiert, während Sie Werte in den Editor eingeben.
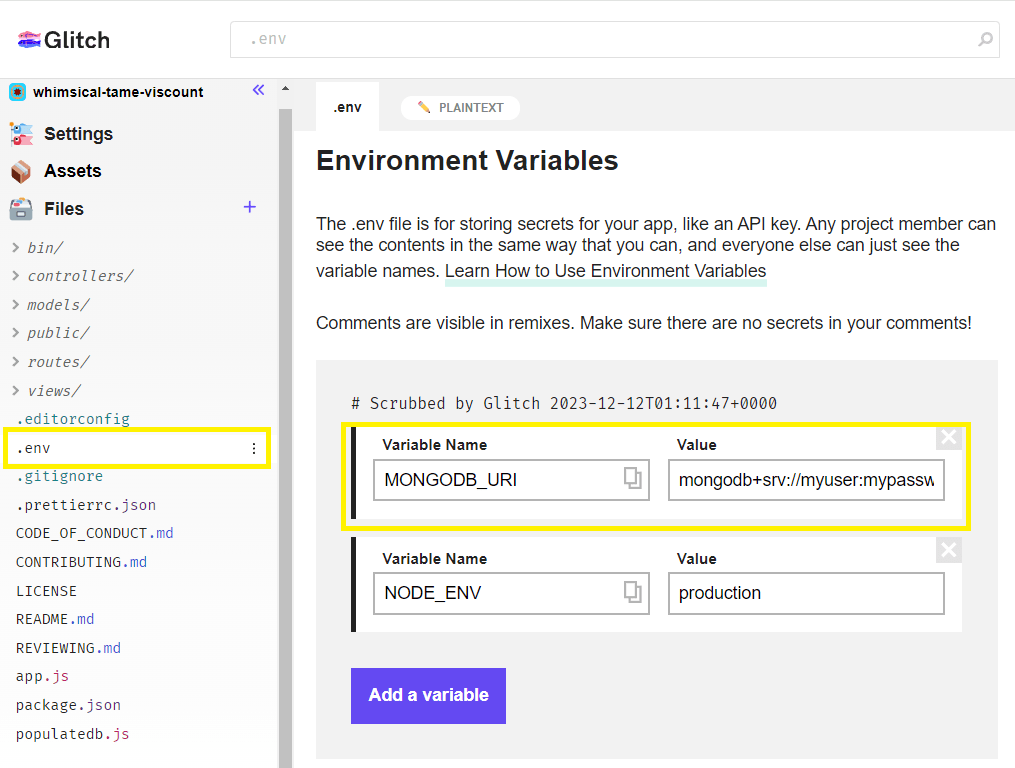
Hinweis: Wir haben diese Datei nicht erstellt. Sie ist für private Daten gedacht und wurde bei einem Import zu Glitch automatisch erstellt. Sie wird nie exportiert oder kopiert.
Andere Konfigurationsvariablen
Sie erinnern sich aus einem vorhergehenden Abschnitt, dass wir NODE_ENV auf 'production':_ setzen müssen, um die Leistung zu verbessern und weniger ausführliche Fehlermeldungen zu erzeugen. Wir tun dies in derselben Datei, wie wir die MONGODB_URI-Variable setzen.
Öffnen Sie .env und fügen Sie eine NODE_ENV-Variable mit dem Wert production hinzu (siehe Screenshot im vorherigen Abschnitt).
Die Lokale Bibliotheksanwendung ist nun eingerichtet und für die Produktionsnutzung konfiguriert. Sie können Daten über die Website-Oberfläche hinzufügen, und es sollte ähnlich wie während der Entwicklung funktionieren (obwohl mit weniger Debug-Informationen, die für ungültige Seiten freigelegt werden).
Hinweis:
Wenn Sie nur einige Daten zu Testzwecken hinzufügen möchten, könnten Sie das populatedb-Script (mit Ihrer MongoDB-Produktionsdatenbank-URL) verwenden, wie im Abschnitt Express-Tutorial Teil 3: Verwenden einer Datenbank (mit Mongoose) Testen — einige Elemente erstellen besprochen.
Debugging von Express-Apps auf Glitch
Glitch ermöglicht effektives Debugging. Einige der Dinge, die Sie tun können, sind:
- Wählen Sie die Protokoll-Schaltfläche unten in der Editor-Ansicht, um Protokollinformationen von Ihrem Server zu sehen, wie Konsolenprotokollausgaben.
- Wählen Sie die Terminal-Schaltfläche unten in der Editor-Ansicht, um ein Terminal in der Hosting-Umgebung zu öffnen.
Sie können damit Befehle und Tools in der Umgebung ausführen.
Zum Beispiel könnten Sie
node -vverwenden, um die Node-Version zu überprüfen. - Interaktive Fehlersuche in VS Code mithilfe der GLITCH-Erweiterung für VS Code.
Beispiel: Hosting auf Railway
Dieser Abschnitt bietet eine praktische Demonstration, wie LocalLibrary auf Railway installiert wird.
Warum Railway?
Warnung: Railway hat keinen vollständig kostenlosen Starter-Tarif mehr. Wir haben diese Anweisungen beibehalten, weil Railway einige großartige Funktionen hat und für einige Benutzer die bessere Option sein wird.
Railway ist aus mehreren Gründen eine attraktive Hosting-Option:
- Railway kümmert sich um die meisten Infrastrukturkomponenten, sodass Sie das nicht müssen. Sich nicht um Server, Load Balancer, Reverse Proxies und dergleichen kümmern zu müssen, macht den Einstieg viel einfacher.
- Railway hat einen Fokus auf Benutzererfahrung für Entwicklung und Bereitstellung, was zu einer schnelleren und weicheren Lernkurve führt als viele andere Alternativen.
- Die Fähigkeiten und Konzepte, die Sie beim Verwenden von Railway lernen, sind übertragbar. Während Railway einige exzellente neue Funktionen hat, verwenden viele andere beliebte Hosting-Dienste viele derselben Ideen und Ansätze.
- Railway-Dokumentation ist klar und vollständig.
- Der Service scheint sehr zuverlässig zu sein, und wenn Sie am Ende begeistert sind, sind die Preise vorhersagbar, und die Skalierung Ihrer App ist sehr einfach.
Sie sollten sich die Zeit nehmen, um festzustellen, ob Railway für Ihre eigene Website geeignet ist.
Wie funktioniert Railway?
Webanwendungen werden jeweils in einem eigenen isolierten und unabhängigen virtualisierten Container ausgeführt. Um Ihre Anwendung auszuführen, muss Railway in der Lage sein, die geeignete Umgebung und Abhängigkeiten einzurichten und auch zu verstehen, wie sie gestartet wird.
Railway macht dies einfach, da es viele verschiedene Webanwendungs-Frameworks und Umgebungen basierend auf ihrer Verwendung von "gemeinsamen Konventionen" automatisch erkennen und installieren kann. Zum Beispiel erkennt Railway Node-Apps, weil sie eine package.json-Datei haben, und kann den verwendeten Paketmanager durch die "Sperr"-Datei ermitteln. Zum Beispiel, wenn die Anwendung die Datei package-lock.json enthält, weiß Railway, dass es npm verwenden soll, um die Pakete zu installieren, während es bei yarn.lock erkennt, dass yarn verwendet werden soll. Nachdem alle Abhängigkeiten installiert sind, wird Railway nach Skripten namens "build" und "start" in der Paketdatei suchen und diese verwenden, um den Code zu bauen und auszuführen.
Hinweis: Railway verwendet Nixpacks, um verschiedene Webanwendungs-Frameworks zu erkennen, die in verschiedenen Programmiersprachen geschrieben sind. Für dieses Tutorial brauchen Sie nichts Weiteres darüber zu erfahren, aber Sie können sich über Optionen zur Bereitstellung von Node-Anwendungen in Nixpacks Node informieren.
Sobald die Anwendung läuft, kann sie sich mit Informationen aus Umgebungsvariablen konfigurieren. Zum Beispiel muss eine Anwendung, die eine Datenbank verwendet, die Adresse über eine Variable abrufen. Der Datenbankservice selbst kann von Railway oder einem anderen Anbieter gehostet werden.
Entwickler interagieren mit Railway über die Railway-Site und mit einem speziellen Command Line Interface (CLI)-Tool. Das CLI erlaubt es Ihnen, ein lokales GitHub-Repository mit einem Railway-Projekt zu verknüpfen, das Repository vom lokalen Zweig auf die Live-Site hochzuladen, die Protokolle des laufenden Prozesses zu inspizieren, Konfigurationsvariablen zu setzen und abzurufen und vieles mehr. Eine der nützlichsten Funktionen ist, dass Sie mit dem CLI Ihr lokales Projekt mit denselben Umgebungsvariablen ausführen können wie das Live-Projekt.
Das ist alles, was Sie an Überblick benötigen, um die App auf Railway bereitzustellen. Als Nächstes richten wir ein Railway-Konto ein, installieren unsere Website und eine Datenbank und probieren das Railway-Client-Tool aus.
Erhalten eines Railway-Kontos
Um Railway verwenden zu können, müssen Sie zunächst ein Konto erstellen:
- Gehen Sie zu railway.com und klicken Sie auf den Login-Link in der oberen Symbolleiste.
- Wählen Sie GitHub im Popup, um sich mit Ihren GitHub-Anmeldeinformationen anzumelden.
- Möglicherweise müssen Sie dann Ihre E-Mail abrufen und Ihr Konto verifizieren.
- Sie werden dann in das Railway-Dashboard eingeloggt: https://railway.com/dashboard.
Bereitstellen auf Railway von GitHub
Als Nächstes richten wir Railway ein, um unsere Bibliothek von GitHub bereit zu stellen. Wählen Sie zuerst die Option Dashboard aus dem oberen Menü der Seite und dann die New Project-Schaltfläche:
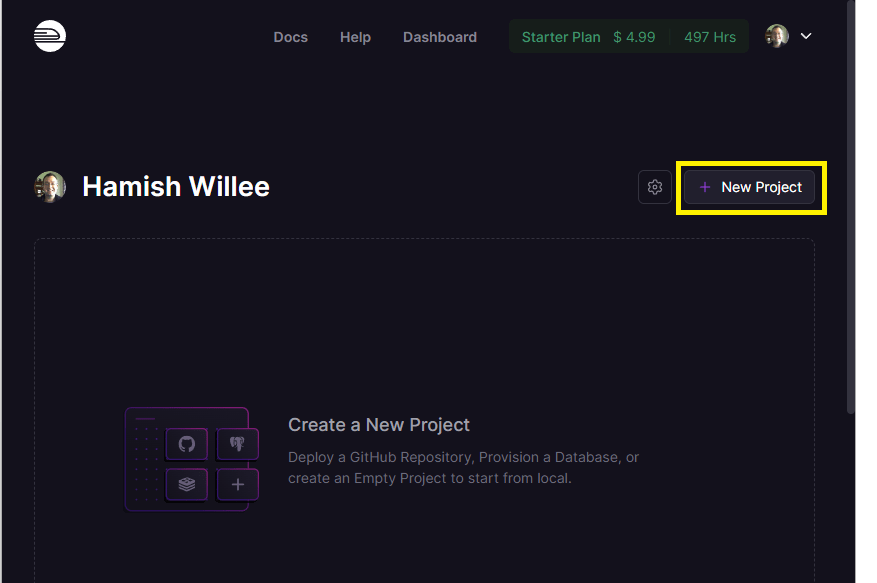
Railway wird eine Liste von Optionen für das neue Projekt anzeigen, einschließlich der Option, ein Projekt aus einer Vorlage zu starten, die zuerst in Ihrem GitHub-Konto erstellt wird, und eine Reihe von Datenbanken. Wählen Sie Deploy from GitHub repo.

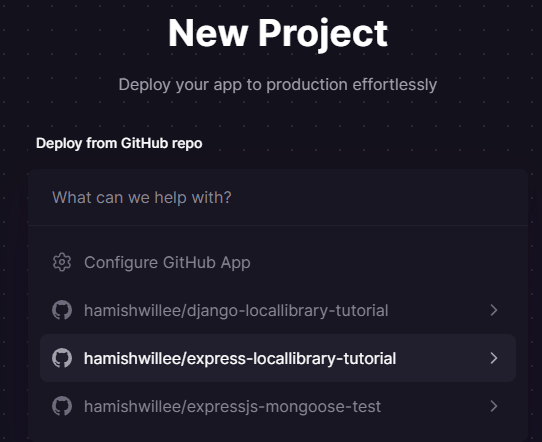
Alle Projekte in den GitHub-Repos, die Sie während der Einrichtung mit Railway geteilt haben, werden angezeigt.
Wählen Sie Ihr GitHub-Repository für die Lokale Bibliothek: <user-name>/express-locallibrary-tutorial.
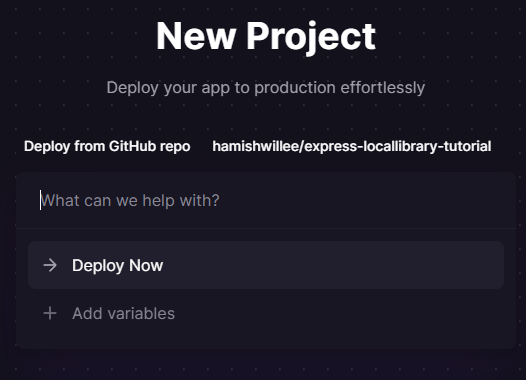
Bestätigen Sie Ihre Bereitstellung, indem Sie Deploy Now auswählen.
Railway wird dann Ihr Projekt laden und bereitstellen, während Sie im Reiter "Deployments" den Fortschritt beobachten können. Wenn die Bereitstellung erfolgreich abgeschlossen ist, sehen Sie einen Bildschirm wie den unten stehenden.
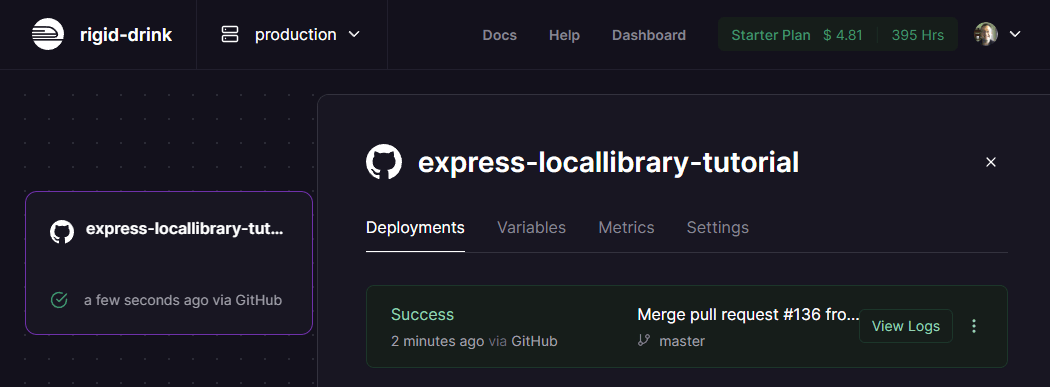
Wählen Sie nun den Settings-Reiter, scrollen Sie nach unten zum Bereich „Domains“ und drücken Sie die Generate Domain-Schaltfläche.
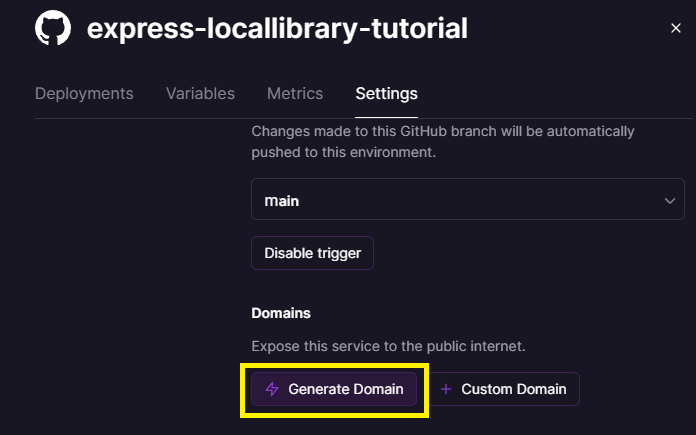
Dadurch wird die Site veröffentlicht und die Domain an der Stelle der Schaltfläche angezeigt, wie unten gezeigt.

Wählen Sie die URL-Domain, um Ihre Bibliotheksanwendung zu öffnen. Denken Sie daran, dass wir keine Produktionsdatenbank spezifiziert haben, also öffnet sich die lokale Bibliothek mit Ihren Entwicklungsdaten.
Bereitstellen und Verbinden einer MongoDB-Datenbank
Anstelle unserer Entwicklungsdaten schaffen wir als Nächstes eine Produktions-MongoDB-Datenbank. Wir werden die Datenbank als Teil des Railway-Anwendungsprojekts erstellen, obwohl Sie sie genauso gut in einem eigenen separaten Projekt erstellen oder tatsächlich eine MongoDB Atlas-Datenbank für Produktionsdaten nutzen könnten, genau wie Sie es für die Entwicklungsdatenbank getan haben.
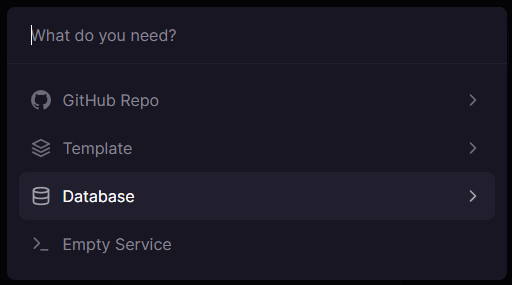
Auf Railway wählen Sie die Option Dashboard aus dem oberen Menü der Seite und dann Ihr Anwendungsprojekt. Zu diesem Zeitpunkt enthält es nur einen Dienst für Ihre Anwendung (dieser kann ausgewählt werden, um Variablen und andere Details des Dienstes einzurichten). Wählen Sie die New-Schaltfläche, um Dienste zum aktuellen Projekt hinzuzufügen.

Wählen Sie Database, wenn gefragt wird, welche Art von Service hinzugefügt werden soll:
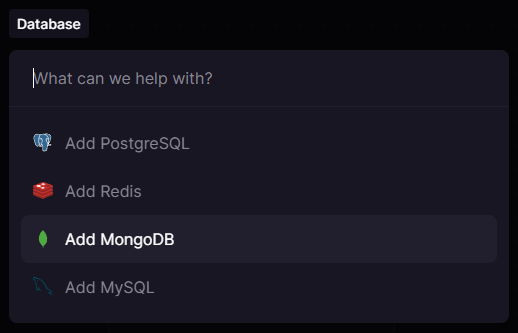
Wählen Sie dann Add MongoDB, um die Datenbank hinzuzufügen.
Railway wird dann einen Dienst bereitstellen, der eine Datenbank in demselben Projekt enthält. Nach Abschluss sehen Sie jetzt sowohl die Anwendungs- als auch die Datenbankdienste in der Projektansicht.
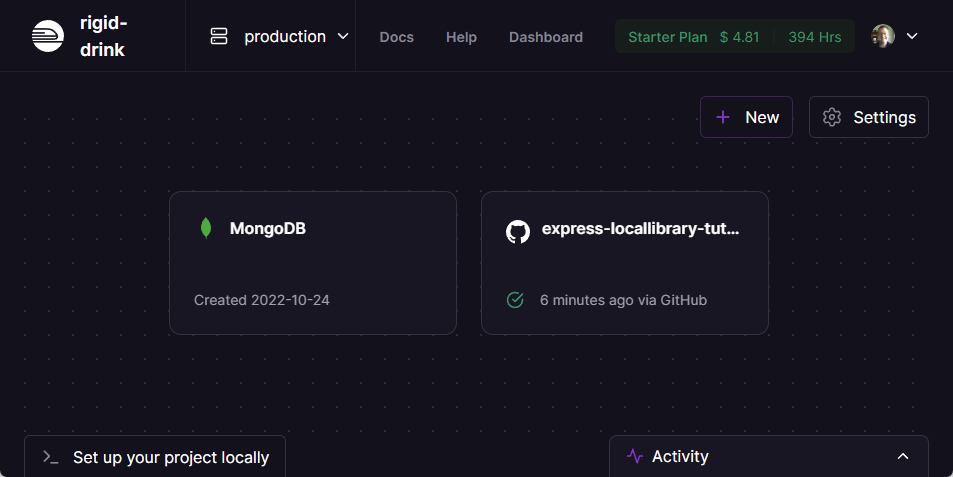
Wählen Sie den MongoDB-Dienst, um Informationen zur Datenbank anzuzeigen. Öffnen Sie den Variables-Reiter und kopieren Sie die „Mongo_URL“ (dies ist die Adresse der Datenbank).
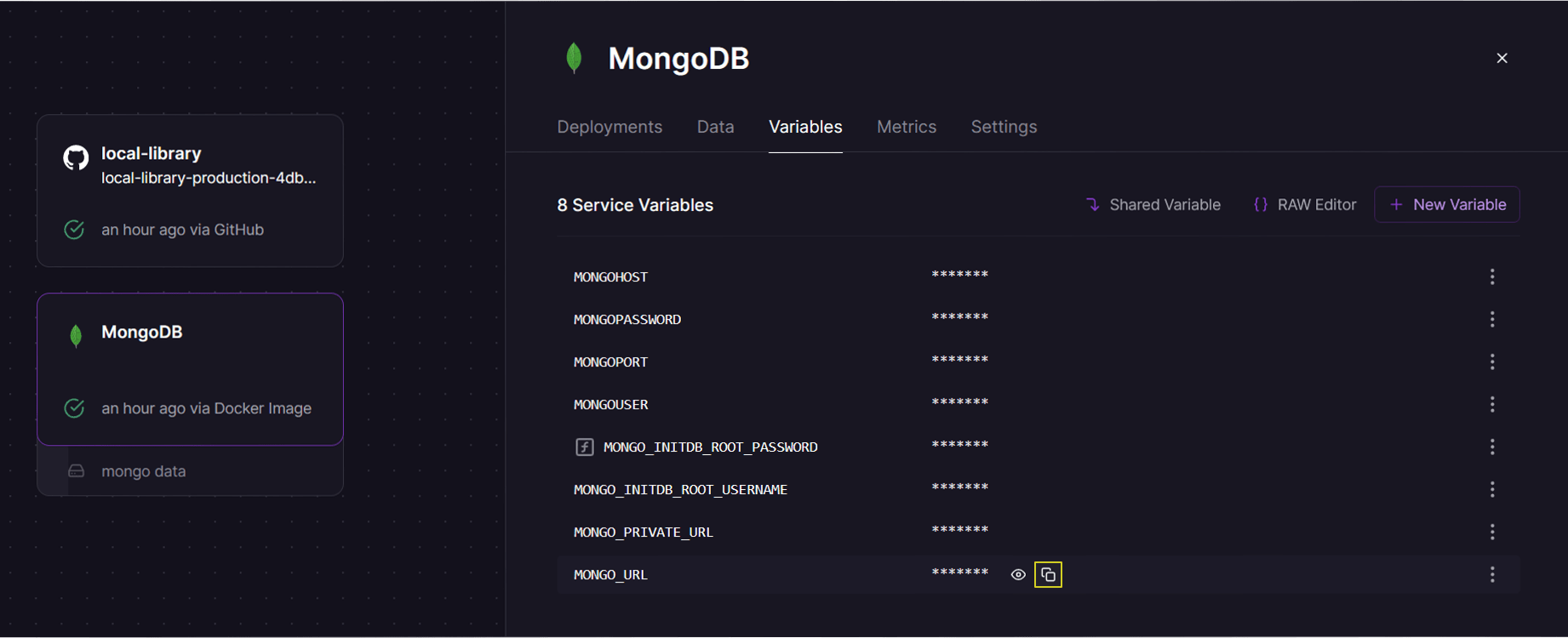
Um den Bibliotheksanwendungen Zugriff auf diese Datenbank zu gewähren, müssen wir sie als Umgebungsvariable zur Anwendung hinzufügen. Öffnen Sie zuerst den Anwendungsdienst. Dann wählen Sie den Variables-Reiter und drücken die New Variable-Schaltfläche.
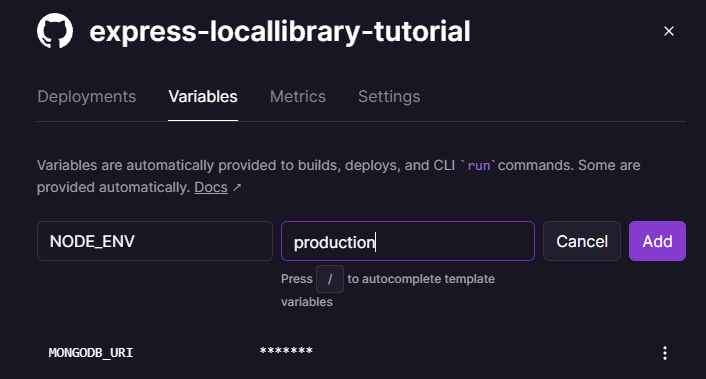
Geben Sie den Variablenname MONGODB_URI und die Verbindungs-URL für die Datenbank ein, die Sie kopiert haben (MONGODB_URI ist der Name der Umgebungsvariable, aus der wir die Anwendung konfiguriert haben, um die Datenbankadresse zu lesen).
Dies wird wie auf dem unten gezeigten Bildschirm aussehen.
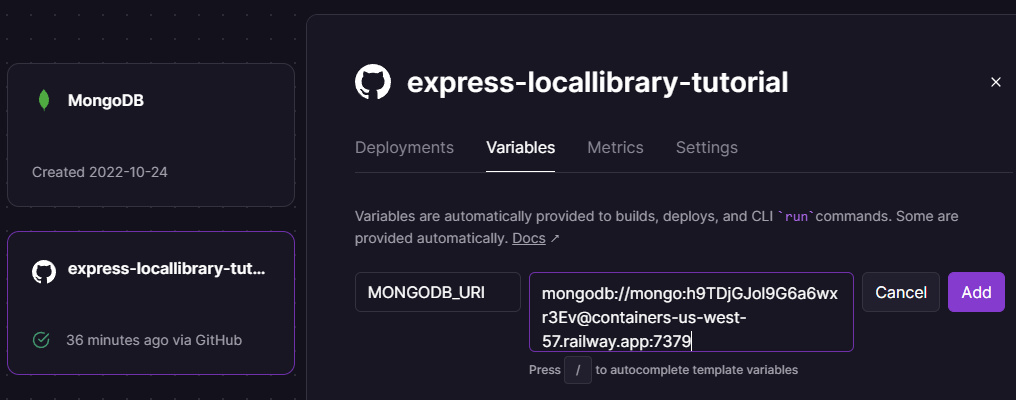
Wählen Sie Add, um die Variable hinzuzufügen.
Railway startet Ihre App neu, wenn es Variablen aktualisiert. Wenn Sie die Startseite jetzt überprüfen, sollte sie null Werte für Ihre Objektanzahlen anzeigen, da die obigen Änderungen bedeuten, dass wir jetzt eine neue (leere) Datenbank verwenden.
Andere Konfigurationsvariablen
Sie erinnern sich aus einem vorhergehenden Abschnitt, dass wir NODE_ENV auf 'production' setzen müssen, um unsere Leistung zu verbessern und weniger ausführliche Fehlermeldungen zu generieren. Wir können dies im selben Bildschirm tun, in welchem wir die MONGODB_URI-Variable gesetzt haben.
Öffnen Sie den Anwendungsdienst.
Dann wählen Sie den Variables-Reiter, wo Sie sehen, dass MONGODB_URI bereits definiert ist, und drücken die New Variable-Schaltfläche.
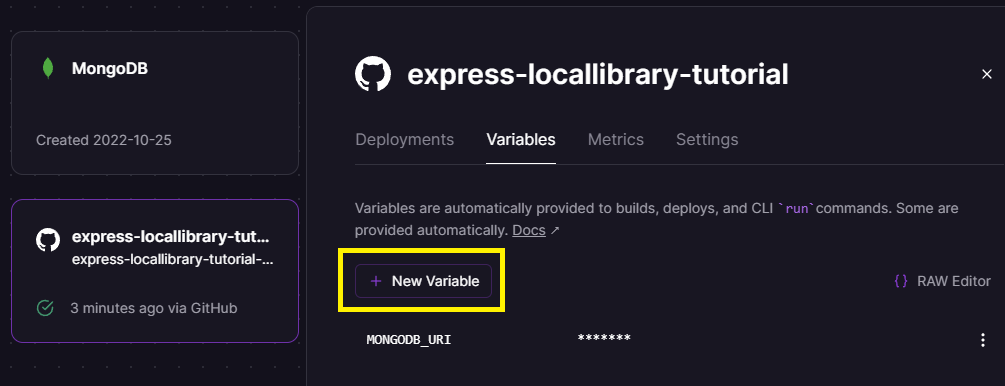
Geben Sie NODE_ENV als Name der neuen Variable und production als Name der Umgebung ein.
Drücken Sie dann die Add-Schaltfläche.
Die LocalLibrary-Anwendung ist nun eingerichtet und für die Produktion konfiguriert. Sie können Daten über die Weboberfläche hinzufügen und es sollte genauso funktionieren wie während der Entwicklung (obwohl mit weniger Debug-Informationen, die für ungültige Seiten freigelegt werden).
Hinweis:
Wenn Sie nur einige Daten zum Testen hinzufügen möchten, könnten Sie das populatedb-Script (mit Ihrer MongoDB-Produktionsdatenbank-URL) verwenden, wie im Abschnitt Express Tutorial Part 3: Using a Database (with Mongoose) Testing — create some items besprochen.
Installieren des Clients
Laden Sie den Railway-Client für Ihr lokales Betriebssystem herunter und installieren Sie ihn, indem Sie die Anleitungen hier befolgen.
Nachdem der Client installiert ist, können Sie Befehle ausführen. Einige der wichtigeren Operationen umfassen das Bereitstellen des aktuellen Verzeichnisses Ihres Computers in einem verbundenen Railway-Projekt (ohne es auf GitHub hochladen zu müssen) und das Ausführen Ihres Projekts lokal mit denselben Einstellungen wie auf dem Produktionsserver.
Sie können eine Liste aller möglichen Befehle abrufen, indem Sie im Terminal Folgendes eingeben.
railway help
Debugging
Der Railway-Client bietet den Befehl logs, um das Ende der Logs anzuzeigen (ein vollständigeres Log ist auf der Site für jedes Projekt verfügbar):
railway logs
Zusammenfassung
Das ist das Ende dieses Tutorials zur Einrichtung von Express-Apps in der Produktion und auch der Serie von Tutorials zur Arbeit mit Express. Wir hoffen, Sie fanden sie nützlich. Sie können sich eine komplett durchgearbeitete Version des Quellcodes auf GitHub hier ansehen.
Siehe auch
-
Produktions-Best-Practices: Leistung und Zuverlässigkeit (Express-Dokumentation)
-
Produktions-Best-Practices: Sicherheit (Express-Dokumentation)
-
Railway-Dokumentation
-
DigitalOcean
-
Heroku
- Getting Started on Heroku with Node.js (Heroku-Dokumentation)
- Deploying Node.js Applications on Heroku (Heroku-Dokumentation)
- Heroku Node.js Support (Heroku-Dokumentation)
- Optimizing Node.js Application Concurrency (Heroku-Dokumentation)
- How Heroku works (Heroku-Dokumentation)
- Dynos und der Dyno-Manager (Heroku-Dokumentation)
- Konfiguration und Konfigurationsvariablen (Heroku-Dokumentation)
- Limits (Heroku-Dokumentation)