Wie Leerzeichen von HTML, CSS und im DOM behandelt werden
Die Anwesenheit von Leerzeichen im DOM kann Layout-Probleme verursachen und die Manipulation des Inhaltsbaums auf unerwartete Weise erschweren, abhängig davon, wo sie sich befinden. Dieser Artikel untersucht, wann Schwierigkeiten auftreten können, und betrachtet, was getan werden kann, um daraus resultierende Probleme abzumildern.
Was sind Leerzeichen?
Leerzeichen sind jede Zeichenkette, die nur aus Leerzeichen, Tabs oder Zeilenumbrüchen besteht (genauer gesagt, CRLF-Sequenzen, Wagenrückläufen oder Zeilenvorschüben). Diese Zeichen ermöglichen es Ihnen, Ihren Code so zu formatieren, dass er für Sie und andere leicht lesbar ist. Tatsächlich ist viel unser Quellcode voll von diesen Leerzeichen, und wir neigen dazu, sie in einem Produktions-Build-Schritt zu entfernen, um die Größe der Code-Downloads zu reduzieren.
HTML ignoriert Leerzeichen weitgehend?
Im Falle von HTML werden Leerzeichen weitgehend ignoriert — Leerzeichen zwischen Wörtern werden als ein einziges Zeichen behandelt, und Leerzeichen am Anfang und Ende von Elementen und außerhalb von Elementen werden ignoriert. Nehmen Sie das folgende minimalistische Beispiel:
<!doctype html>
<h1> Hello World! </h1>
Dieser Quellcode enthält ein paar Zeilenvorschübe nach dem doctype und eine Menge Leerzeichen vor, nach und innerhalb des <h1> Elements, aber der Browser scheint sich überhaupt nicht darum zu kümmern und zeigt einfach die Worte "Hello World!" an, als ob diese Zeichen überhaupt nicht existierten:
Dies dient dazu, dass Leerzeichen-Zeichen Ihr Seitenlayout nicht beeinträchtigen. Räume um und in Elementen zu schaffen, ist die Aufgabe von CSS.
Was passiert mit Leerzeichen?
Sie verschwinden jedoch nicht einfach.
Alle Leerzeichen, die sich außerhalb von HTML-Elementen im Originaldokument befinden, sind im DOM dargestellt. Dies ist intern erforderlich, damit der Editor die Formatierung von Dokumenten beibehalten kann. Das bedeutet:
- Es wird einige Textknoten geben, die nur Leerzeichen enthalten, und
- Einige Textknoten werden Leerzeichen am Anfang oder Ende haben.
Nehmen Sie zum Beispiel folgendes Dokument:
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
Der DOM-Baum dafür sieht folgendermaßen aus:

Das Beibehalten von Leerzeichen im DOM ist auf viele Arten nützlich, aber es gibt bestimmte Stellen, an denen dies bestimmte Layouts schwieriger umzusetzen macht und Probleme für Entwickler verursacht, die durch Knoten im DOM iterieren möchten. Wir werden uns dies und einige Lösungen später genauer ansehen.
Wie verarbeitet CSS Leerzeichen?
Die meisten Leerzeichen-Zeichen werden ignoriert, aber nicht alle. Im vorherigen Beispiel existiert eines der Leerzeichen zwischen "Hello" und "World!" weiterhin, wenn die Seite in einem Browser gerendert wird. Es gibt Regeln in der Browser-Engine, die entscheiden, welche Leerzeichen nützlich sind und welche nicht — diese sind zumindest teilweise im CSS Text Module Level 3 spezifiziert, insbesondere die Teile über die CSS white-space Eigenschaft und Details zur Verarbeitung von Leerzeichen, aber wir bieten unten auch eine einfachere Erklärung an.
Beispiel
Nehmen wir ein weiteres Beispiel. Um es einfacher zu machen, haben wir einen Kommentar hinzugefügt, der alle Leerzeichen mit ◦, alle Tabs mit ⇥ und alle Zeilenumbrüche mit ⏎ anzeigt:
Dieses Beispiel:
<h1> Hello
<span> World!</span> </h1>
<!--
<h1>◦◦◦Hello◦⏎
⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>
-->
wird im Browser wie folgt gerendert:
Erklärung
Das <h1> Element enthält nur Inline-Elemente. Tatsächlich enthält es:
- Einen Textknoten (bestehend aus einigen Leerzeichen, dem Wort "Hello" und einigen Tabs).
- Ein Inline-Element (das
<span>, das ein Leerzeichen und das Wort "World!" enthält). - Einen weiteren Textknoten (bestehend nur aus Tabs und Leerzeichen).
Deshalb etabliert es das, was als ein Inline-Formatting-Kontext bezeichnet wird. Dies ist einer der möglichen Layout-Rendering-Kontexte, mit denen Browser-Engines arbeiten.
Innerhalb dieses Kontextes kann die Verarbeitung von Leerzeichen wie folgt zusammengefasst werden:
-
Zuerst werden alle Leerzeichen und Tabs, die unmittelbar vor und nach einem Zeilenumbruch stehen, ignoriert, sodass, wenn wir unsere Beispiel-Markup nehmen:
html<h1>◦◦◦Hello◦⏎ ⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>...und diese erste Regel anwenden, erhalten wir:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>⇥◦◦</h1> -
Als nächstes werden alle Tab-Zeichen wie Leerzeichen behandelt, sodass das Beispiel wird zu:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>◦◦◦</h1> -
Danach werden Zeilenumbrüche in Leerzeichen umgewandelt:
html<h1>◦◦◦Hello◦<span>◦World!</span>◦◦◦</h1> -
Danach wird jedes Leerzeichen, das einem anderen Leerzeichen unmittelbar folgt (auch zwischen zwei separaten Inline-Elementen), ignoriert, sodass wir enden mit:
html<h1>◦Hello◦<span>World!</span>◦</h1> -
Und schließlich werden Leerzeichensequenzen am Anfang und Ende eines Elements entfernt, sodass wir schließlich dies erhalten:
html<h1>Hello◦<span>World!</span></h1>
Deswegen werden Besucher der Webseite den Satz "Hello World!" schön geschrieben oben auf der Seite sehen, anstatt eines merkwürdig eingerückten "Hello" gefolgt von einem noch merkwürdiger eingerückten "World!" auf der Zeile darunter.
Hinweis:>Firefox DevTools unterstützen seit Version 52 das Hervorheben von Textknoten, was es einfacher macht, genau zu sehen, welche Knoten Leerzeichen enthalten. Reine Leerzeichenknoten sind mit einem "whitespace"-Label gekennzeichnet.
Leerzeichen in Blockformatierungskontexten
Oben haben wir uns Elemente angeschaut, die Inline-Elemente enthalten, und Inline-Formatting-Kontexte. Wenn ein Element mindestens ein Block-Element enthält, dann etabliert es stattdessen das, was als Block-Formatting-Kontext bezeichnet wird.
In diesem Kontext werden Leerzeichen sehr unterschiedlich behandelt.
Beispiel
Werfen wir einen Blick auf ein Beispiel, um zu erklären, wie. Wir haben die Leerzeichen-Zeichen wie zuvor markiert.
Wir haben 3 Textknoten, die nur Leerzeichen enthalten, einen vor dem ersten <div>, einen zwischen den 2 <div>s, und einen nach dem zweiten <div>.
<body>
<div> Hello </div>
<div> World! </div>
</body>
<!--
<body>⏎
⇥<div>◦◦Hello◦◦</div>⏎
⏎
◦◦◦<div>◦◦World!◦◦</div>◦◦⏎
</body>
-->
Dies wird wie folgt gerendert:
Erklärung
Wir können zusammenfassen, wie die Leerzeichen hier behandelt werden (es kann einige leichte Unterschiede im genauen Verhalten zwischen den Browsern geben, aber im Wesentlichen funktioniert dies):
-
Da wir uns in einem Block-Formatting-Kontext befinden, muss alles ein Block sein, also werden unsere 3 Textknoten auch zu Blöcken, genau wie die 2
<div>s. Blöcke nehmen die volle verfügbare Breite ein und sind übereinander gestapelt, was bedeutet, dass, ausgehend vom obigen Beispiel:html<body>⏎ ⇥<div>◦◦Hello◦◦</div>⏎ ⏎ ◦◦◦<div>◦◦World!◦◦</div>◦◦⏎ </body>...wir mit einem Layout enden, das aus dieser Liste von Blöcken besteht:
html<block>⏎⇥</block> <block>◦◦Hello◦◦</block> <block>⏎⏎◦◦◦</block> <block>◦◦World!◦◦</block> <block>◦◦⏎</block> -
Dies wird dann weiter vereinfacht, indem die Verarbeitungsregeln für Leerzeichen in Inline-Formatting-Kontexten auf diese Blöcke angewendet werden:
html<block></block> <block>Hello</block> <block></block> <block>World!</block> <block></block> -
Die 3 leeren Blöcke, die wir jetzt haben, werden im endgültigen Layout keinen Platz einnehmen, da sie nichts enthalten, also werden wir am Ende nur 2 Blöcke haben, die Platz auf der Seite einnehmen. Personen, die die Webseite besuchen, sehen die Wörter "Hello" und "World!" auf 2 separaten Zeilen, wie Sie es erwarten würden, dass 2
<div>s zusammen angezeigt werden. Die Browser-Engine hat im Wesentlichen alle Leerzeichen ignoriert, die im Quellcode hinzugefügt wurden.
Leerzeichen zwischen Inline- und Inline-Block-Elementen
Lassen Sie uns über einige Probleme sprechen, die aufgrund von Leerzeichen auftreten können, und was dagegen getan werden kann. Zuerst schauen wir uns an, was mit Leerzeichen zwischen Inline- und Inline-Block-Elementen passiert. Tatsächlich haben wir das bereits in unserem allerersten Beispiel gesehen, als wir beschrieben haben, wie Leerzeichen in Inline-Formatting-Kontexten verarbeitet werden.
Wir sagten, dass es Regeln gibt, um die meisten Zeichen zu ignorieren, aber dass worttrennende Zeichen bestehen bleiben. Wenn Sie nur mit Block-Elementen wie <p> arbeiten, die nur Inline-Elemente wie <em>, <strong>, <span>, usw. enthalten, achten Sie in der Regel nicht darauf, da das zusätzliche Leerzeichen, das tatsächlich ins Layout gelangt, hilfreich ist, um die Wörter im Satz zu trennen.
Es wird jedoch interessanter, wenn Sie beginnen, inline-block Elemente zu verwenden. Diese Elemente verhalten sich auf der Außenseite wie Inline-Elemente und auf der Innenseite wie Blöcke und werden oft verwendet, um komplexere UI-Stücke als nur Text nebeneinander auf der gleichen Linie anzuzeigen, z.B. Navigationselemente.
Da sie Blöcke sind, erwarten viele Menschen, dass sie sich auch so verhalten, aber das tun sie nicht wirklich. Wenn zwischen angrenzenden Inline-Elementen Formatierungs-Leerzeichen vorhanden sind, führt dies dazu, dass im Layout Raum entsteht, genau wie die Leerzeichen zwischen Wörtern im Text.
Beispiel
Betrachten Sie dieses Beispiel (wir haben wieder einen HTML-Kommentar hinzugefügt, der die Leerzeichen-Zeichen im HTML zeigt):
.people-list {
list-style-type: none;
margin: 0;
padding: 0;
}
.people-list li {
display: inline-block;
width: 2em;
height: 2em;
background: #f06;
border: 1px solid;
}
<ul class="people-list">
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul>
<!--
<ul class="people-list">⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
</ul>
-->
Dies wird wie folgt gerendert:
Sie möchten wahrscheinlich nicht die Lücken zwischen den Blöcken — abhängig von Anwendungsfall (ist dies eine Liste von Avataren oder horizontale Navigationsknöpfe?), möchten Sie wahrscheinlich, dass die Kanten der Elemente bündig zueinander sind und dass Sie jeden Abstand selbst kontrollieren können.
Der HTML-Inspektor von Firefox DevTools hebt Textknoten hervor und zeigt Ihnen auch genau, welchen Bereich die Elemente einnehmen — nützlich, wenn Sie sich fragen, was das Problem verursacht, und vielleicht denken, Sie hätten dort einen zusätzlichen Rand oder so etwas!
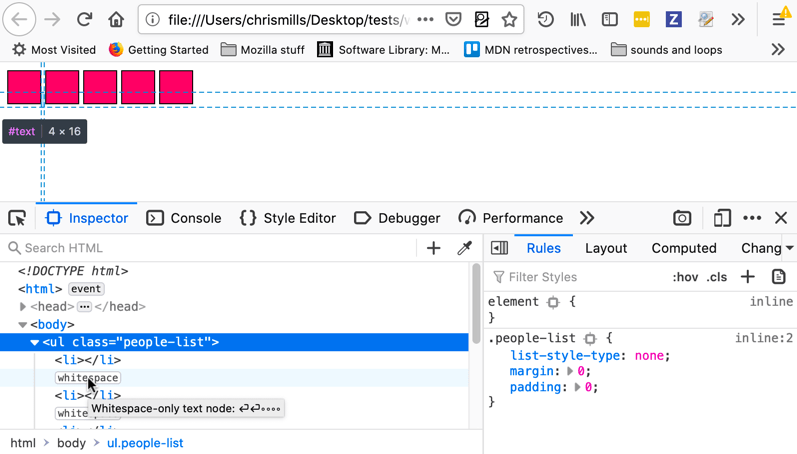
Lösungen
Es gibt einige Möglichkeiten dieses Problem zu umgehen:
Verwenden Sie Flexbox, um die horizontale Liste von Elementen zu erstellen, anstatt eine inline-block Lösung zu versuchen. Dies erledigt alles für Sie und ist definitiv die bevorzugte Lösung:
ul {
list-style-type: none;
margin: 0;
padding: 0;
display: flex;
}
Wenn Sie auf inline-block angewiesen sein müssen, könnten Sie die font-size der Liste auf 0 setzen. Dies funktioniert nur, wenn Ihre Blöcke nicht mit ems (basierend auf der font-size, sodass die Blockgröße auch auf 0 enden würde) bemessen sind. rems wären hier eine gute Wahl:
ul {
font-size: 0;
/* … */
}
li {
display: inline-block;
width: 2rem;
height: 2rem;
/* … */
}
Oder Sie könnten einen negativen Rand bei den Listenelementen setzen:
li {
display: inline-block;
width: 2rem;
height: 2rem;
margin-right: -0.25rem;
}
Sie können dieses Problem auch lösen, indem Sie Ihre Listenelemente alle in derselben Zeile im Quellcode setzen, was dazu führt, dass die Leerzeichenknoten erst gar nicht erstellt werden:
<li></li><li></li><li></li><li></li><li></li>
DOM-Durchlauf und Leerzeichen
Beim Versuch, DOM Manipulationen in JavaScript durchzuführen, können auch Probleme aufgrund von Leerzeichenknoten auftreten. Wenn Sie beispielsweise eine Referenz auf einen übergeordneten Knoten haben und dessen erstes Element-Kind mit Node.firstChild beeinflussen möchten, bekommen Sie nicht das erwartete Ergebnis, falls ein überflüssiger Leerzeichenknoten direkt nach dem öffnenden Eltern-Tag vorhanden ist. Der Textknoten würde anstelle des gewünschten Elements ausgewählt.
Ein weiteres Beispiel: Wenn Sie eine bestimmte Teilmenge von Elementen haben, auf die Sie basierend auf ihrem Inhalt etwas anwenden möchten (ob sie leer sind, d.h. keine Knoten enthalten, oder nicht), könnten Sie überprüfen, ob jedes Element leer ist, indem Sie etwas wie Node.hasChildNodes() verwenden, aber wieder: wenn Ziel-Elemente Textknoten enthalten, könnten Sie falsche Ergebnisse erhalten.
Hilfsfunktionen für Leerzeichen
Das folgende JavaScript definiert mehrere Funktionen, die es einfacher machen, mit Leerzeichen im DOM umzugehen:
/**
* Throughout, whitespace is defined as one of the characters
* "\t" TAB \u0009
* "\n" LF \u000A
* "\r" CR \u000D
* " " SPC \u0020
*
* This does not use JavaScript's "\s" because that includes non-breaking
* spaces (and also some other characters).
*/
/**
* Determine whether a node's text content is entirely whitespace.
*
* @param nod A node implementing the `CharacterData` interface (i.e.,
* a `Text`, `Comment`, or `CDATASection` node)
* @return `true` if all of the text content of `nod` is whitespace,
* otherwise `false`.
*/
function isAllWs(nod) {
return !/[^\t\n\r ]/.test(nod.textContent);
}
/**
* Determine if a node should be ignored by the iterator functions.
*
* @param nod An object implementing the `Node` interface.
* @return `true` if the node is:
* 1) A `Text` node that is all whitespace
* 2) A `Comment` node
* and otherwise `false`.
*/
function isIgnorable(nod) {
return (
nod.nodeType === 8 || // a comment node
(nod.nodeType === 3 && isAllWs(nod))
); // a text node, all ws
}
/**
* Version of `previousSibling` that skips nodes that are entirely
* whitespace or comments. (Normally `previousSibling` is a property
* of all DOM nodes that gives the sibling node, the node that is
* a child of the same parent, that occurs immediately before the
* reference node.)
*
* @param sib The reference node.
* @return The closest previous sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null` if
* no such node exists.
*/
function nodeBefore(sib) {
while ((sib = sib.previousSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `nextSibling` that skips nodes that are entirely
* whitespace or comments.
*
* @param sib The reference node.
* @return The closest next sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null`
* if no such node exists.
*/
function nodeAfter(sib) {
while ((sib = sib.nextSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `lastChild` that skips nodes that are entirely
* whitespace or comments. (Normally `lastChild` is a property
* of all DOM nodes that gives the last of the nodes contained
* directly in the reference node.)
*
* @param sib The reference node.
* @return The last child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function lastChild(par) {
let res = par.lastChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.previousSibling;
}
return null;
}
/**
* Version of `firstChild` that skips nodes that are entirely
* whitespace and comments.
*
* @param sib The reference node.
* @return The first child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function firstChild(par) {
let res = par.firstChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.nextSibling;
}
return null;
}
/**
* Version of `data` that doesn't include whitespace at the beginning
* and end and normalizes all whitespace to a single space. (Normally
* `data` is a property of text nodes that gives the text of the node.)
*
* @param txt The text node whose data should be returned
* @return A string giving the contents of the text node with
* whitespace collapsed.
*/
function dataOf(txt) {
let data = txt.textContent;
data = data.replace(/[\t\n\r ]+/g, " ");
if (data[0] === " ") {
data = data.substring(1, data.length);
}
if (data[data.length - 1] === " ") {
data = data.substring(0, data.length - 1);
}
return data;
}
Beispiel
Der folgende Code demonstriert die Verwendung der obigen Funktionen. Er iteriert über die Kinder eines Elements (dessen Kinder alle Elemente sind), um dasjenige zu finden, dessen Text "This is the third paragraph" ist, und ändert dann das class-Attribut und den Inhalt dieses Absatzes.
let cur = firstChild(document.getElementById("test"));
while (cur) {
if (dataOf(cur.firstChild) === "This is the third paragraph.") {
cur.className = "magic";
cur.firstChild.textContent = "This is the magic paragraph.";
}
cur = nodeAfter(cur);
}